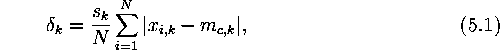There were three data sets of the technological aspects of pulp and paper industry. The first one included information on the production capacities of the mills, the second included information on the technology of the paper machines and the third on the technology of the pulp lines.
Each mill could contain several paper machines and pulp lines and therefore a hierarchical structure of maps was used (see figure 5.1). First two low level maps were constructed from the paper machine and pulp line data sets. These maps provided a clustering of the different machine types. The actual technology-map was trained using the mill-specific info in the mill data set and the data histograms from the two low-level maps.
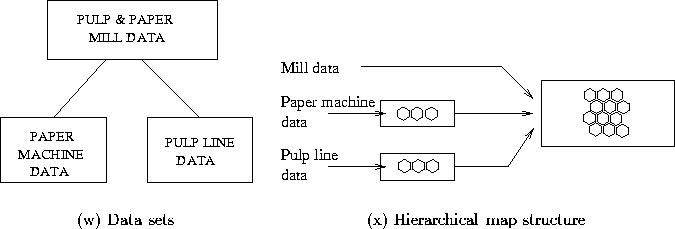
Figure 5.1: (a) There were three technological data sets: one of
mill production capacities, one of paper machines and one
of pulp lines. Each mill could contain several paper machines
and pulp lines. (b) The hierarchical map structure.
Data histrograms from the two smaller maps were utilized
in the training of the third map. The arrows show which data
sets were used in training the maps.
To get a better idea of the precision of the maps for different vector
components, the mean deviations were calculated for each component.
The deviation for component k in vector ![]() is the absolute
difference between the component values in the vector and in its BMU
is the absolute
difference between the component values in the vector and in its BMU
![]() :
: ![]() . It is averaged over all testing
vectors and finally returned to the original value range by
multiplying it by the component scaling factor
. It is averaged over all testing
vectors and finally returned to the original value range by
multiplying it by the component scaling factor ![]() :
:
where ![]() is the value of the kth component of input vector
is the value of the kth component of input vector
![]() and
and ![]() is its BMU.
is its BMU.