 |
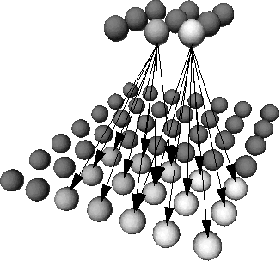
The idea of tree-search for mixture densities has been used without the SOM structure, e.g. in [Seide, 1995]. The loss of accuracy in tree-search follows from the sequential branching decisions by which most of the units are eliminated from the individual inspection. The neighboring search areas for tree-search SOM can be made slightly overlapping for better cover and search accuracy. For K-best search the effect of the branching decisions is softened as well by expanding the search into the lower layer search areas associated with the rival best-matches from the upper layer.
The MDHMM training with the tree-search SOM can be made much like the training with the normal SOM. The codebook is first trained with pre-segmented samples proceeding from the smallest SOM layer on the top towards the largest layer at the bottom. The main exception from the normal SOM algorithm is that the neighborhoods are pre-specified for each layer. When the upper layers are ready they are fixed and used to determine the search areas and the adjusted set of units for the next layer. The Gaussian kernels are finally trained using the lowest layer units. In MDHMM density estimation the upper layers are just search tools that limit the search area and their match values do not (directly) affect the approximated probability value. The adjustments of the mixture densities necessary to optimize the MDHMM performance also affect only the bottom layer of the codebook.
The results of the experiments with MDHMMs reported in Publication 5 indicate that the tree-search SOM can be used as a slightly more inaccurate but faster substitute to the normal SOM codebook. In the comparison by ASR tests against the corresponding MDHMM with normal SOM codebooks, the tree-search SOM, in which the total recognition time decreased by 20 %, increased the average number of recognition errors by 14 %.
For multiprocessor implementations the utility of these search methods is probably small, because the parallelization of the complete search may shift the bottle-neck of the recognition time elsewhere in the process. Compared to the rapid capacity improvements in the general-purpose workstations, the significance of the described speed-ups concerns only situations, where some system must be made to work online on a certain computer. The idea was mainly to show some direct ways to exploit the ordered mapping generated automatically by the SOM, which does not depend as much on the data dimensionality or memory size as some traditional search methods do. Both the training by using the neighborhood smoothing and the topology based fast search methods are expected to scale well for larger dimensions and codebook sizes.