Yksinkertaisin mittari kartan erottelukyvyn mittaamiseksi on
keskimääräinen kvantisointivirhe ![]() :
:
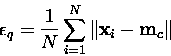 |
(8) |
Kahden kartan vertaaminen toisiinsa kvantisointivirheen avulla ei ole aina järkevää, sillä suuremmalla kartalla voidaan tietysti kvantisoida opetusjoukko tarkemmin. Samoin on ilmeistä, että pienempi naapuruston säde opetuksessa tuottaa usein tarkemman kvantisoinnin, sillä mallivektorit voivat liikkua toisistaan suuremmin välittämättä. Vasta samankokoisten ja samalla naapurustofunktiolla opetettujen karttojen vertailu on mielekästä [24].
Data on yleensä korkeampiulotteista kuin kartan hilarakenne, siis
![]() . Kartta pyrkii tällöin mallintamaan
datajoukkoa laskostumalla kuten kuvassa 2.2.
. Kartta pyrkii tällöin mallintamaan
datajoukkoa laskostumalla kuten kuvassa 2.2.
Kartan laskostumattomuuden eli kuvauksen jatkuvuuden merkitys
on tärkeä esimerkiksi visualisoinnin kannalta: repaleinen kuvaus ei
kerro kartan tulkitsijalle selkeästi näytteiden keskinäisistä
suhteista, ja virhetulkintojen mahdollisuus kasvaa. Kuvauksen
jatkuvuutta kuvataan topografisella virheellä ![]() .
Tämän työn yhdessä aihepiirissä, prosessien monitoroinnissa,
on topografinen virhe todettu tärkeäksi ongelmaksi [19].
.
Tämän työn yhdessä aihepiirissä, prosessien monitoroinnissa,
on topografinen virhe todettu tärkeäksi ongelmaksi [19].
Esimerkkinä tarkastellaan kahta kaksiulotteista karttaa, jotka on opetettu samalla yksikkökuutioon tasan jakautuneella pseudosatunnaisdatalla. Molemmat kartat on alustettu samoin (kuva 2.2(a)). Kartta kuvassa 2.2(b) on järjestynyt. Se täyttää kartan topologian säilyttävän ominaisuuden paremmin kuin kuvan 2.2(c) kartta, mutta sen kvantisointivirhe jää suuremmaksi. Jälkimmäinen kartta on puolestaan voimakkaammin laskostunut, jolloin lähellä toisiaan olevat datavektorit kuvautuvat useammin hilassa toisistaan kaukana oleviin karttayksiköihin.
Topografisia virhemittoja on ehdotettu useita. Yhteenvetoja löytyy
esimerkiksi lähteistä [18,41]. Yksinkertainen topografinen
virhemitta on Kiviluodon esittämä [20]. Lasketaan
kullekin datavektorille ![]() kaksi lähintä yksikköä
kaksi lähintä yksikköä
![]() ja
ja ![]() . Lasketaan kuinka monen datavektorin
voittajayksikköparit
. Lasketaan kuinka monen datavektorin
voittajayksikköparit ![]() ja
ja ![]() eivät ole toistensa
välittömiä naapureita hilassa. Virhemitta on tämän määrän suhde
datavektorien määrään, siis:
eivät ole toistensa
välittömiä naapureita hilassa. Virhemitta on tämän määrän suhde
datavektorien määrään, siis:
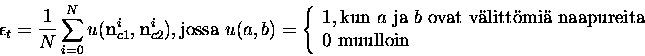 |
(9) |
Yksinkertaisuuden lisäksi tämän mitan etu on erilaisten karttojen ja datajoukkojen virheitten vertailukelpoisuus [42], koska karttojen koko, datan määrä ja muut parametrit eivät selvästikään vaikuta tämän virhemitan skaalaan.
![\begin{figure}
\begin{center}
\subfigure[Lineaarinen alustus]{
\epsfig {file=kuv...
... {file=kuvat/teoria/laskost3.eps, width=.45\textwidth}
}\end{center}\end{figure}](img48.gif) |
Kaski ja Lagus ovat ehdottaneet yhdistettyä mittaa, topografista
kvantisointivirhettä ![]() , jossa erottelykyvyn ja
jatkuvuuden mitat yhdistetään [18]. Mitta on summa kahdesta
etäisyydestä: Lasketaan syötevektorin etäisyys voittajayksikköön
, jossa erottelykyvyn ja
jatkuvuuden mitat yhdistetään [18]. Mitta on summa kahdesta
etäisyydestä: Lasketaan syötevektorin etäisyys voittajayksikköön ![]() , siis kvantisointivirhe. Tähän lisätään lyhin mahdollinen
etäisyys
, siis kvantisointivirhe. Tähän lisätään lyhin mahdollinen
etäisyys ![]() niistä etäisyyksistä, jotka
saadaan
niistä etäisyyksistä, jotka
saadaan ![]() ja
ja ![]() välille aina vierekkäisestä
yksiköstä toiseen kulkien. Kartan yhdistetty virhe datajoukon suhteen
on datajoukon vektoreiden virheiden keskiarvo. Toisin sanoen
(viitteen [41] merkintätapaa mukaellen)
välille aina vierekkäisestä
yksiköstä toiseen kulkien. Kartan yhdistetty virhe datajoukon suhteen
on datajoukon vektoreiden virheiden keskiarvo. Toisin sanoen
(viitteen [41] merkintätapaa mukaellen)
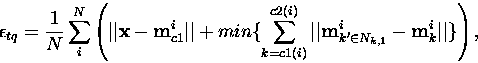 |
(10) |
jossa k korvataan k':lla jokaisen summausaskeleen jälkeen. Nk,1 tarkoittaa yksikön ![]() lähimpiä naapureita hilassa.
lähimpiä naapureita hilassa.