
Laboratory of Computer and Information Science > Teaching > T-61.5060 > Exercises 2007 > Solutions 6
K-means does fulfill the scale invariance as is easily seen. The algorithm never cares about the absolute distances, but just compares them to each other. Calculating the mean is a linear function so that remains the same too.
Furthermore K-means fulfills the richness criteria if and only if we can adjust K based on the partition asked for. One can just distribute the "real" clusters so far away from each other so that each cluster gets one centroid in some case. Then K-means will give the required partition. If on the other hand K is constant, then we obviously can't generate partitions into a larger or smaller amount of clusters.
So what about consistency? One could at first think that yeah sure it works, especially because richness is not fulfilled. But actually K-means is not consistent due to the fact that it depends on other too than just the distances between points. It needs to know the locations of the points and instances with very different centroids can yield same clusterings yet very small changes in the centroids may also change the clustering.
Suppose we have a large cluster X and a very small cluster Y in some "suitably high dimension", distances between x's equal r, Y is a very very tight cluster and distances from X to Y are always a bit more than r. With suitable selections K-means will converge to clusters X and Y.
Now divide X to two equal parts and start shrinking the distances inside these parts. Eventually the shear mass of X's parts will force K-means to simply use the X's parts as clusters and the redistribute Y to those in some way.
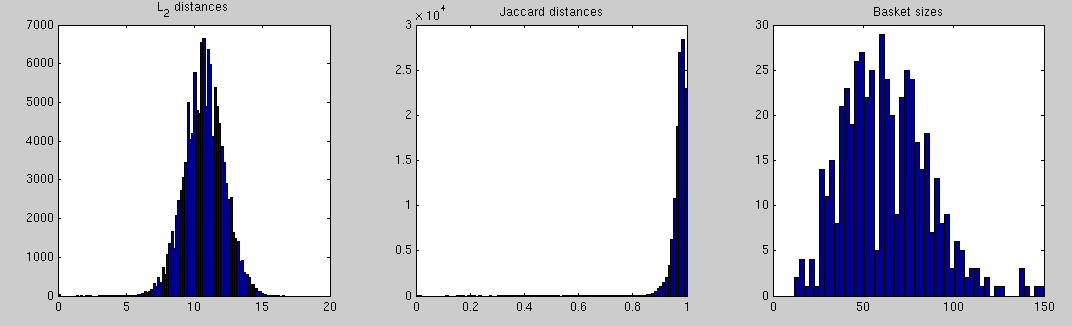
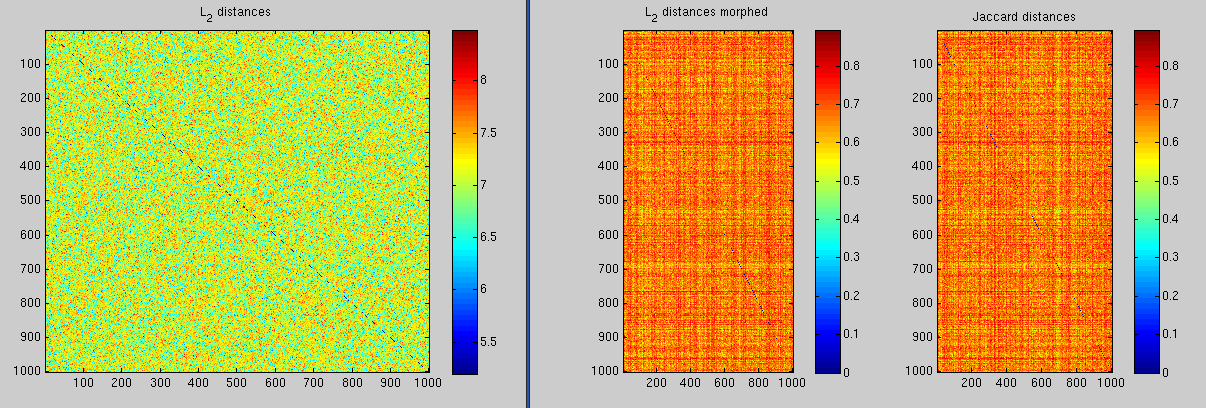
The two pictures tell about the same thing, customers are usually quite different. Looking at the sums, most people buy about 60 pieces of stuff so their difference could be about 120 or a bit less (bread n' butter perhaps?). Now the square root of this is about 11, which is pretty close to what the L_2 norm's figure says. Similarly now the Jaccard distance is naturally very close to one.
Ruby script that changes market-basket sparse
format into Matlab sparse format.
Matlab script for the problem.
Some Matlab plots.
The L_2 norm squared is simply the number of places where the vectors differ. As the vectors are binary ones, this can be seen to equal the symmetric difference a Δ b. But Jaccard distance is actually the symmetric difference (union minus intersection) divided by the union. Therefore J(x,y) = d_2(x,y)^2 / |x \cup y|.
The positiveness condition is obviously fulfilled as a union of sets is always a superset of the intersection and they collide only when the sets compared are equal. These set operations are also symmetric giving us the second condition.
The triangle inequality: All those in favour of grinding can do this manually. There does also exist a proof based on the comparison of probabilities, but it requires some finesse. The script below will calculate the stuff in the inequality stuff >= 0 and dump it. You can then check that grep - jaccardMess gives out nothing so all the terms of the expression are positive signed and so the claim is true.
You are at: CIS → T-61.5060 Exercises 2007, Solutions 6
Page maintained by t615060@james.hut.fi, last updated Thursday, 08-Nov-2007 17:27:39 EET
{kind=link}
{kind=link}