|
Tarkemmalla tukimisilla huomataan, että taulukossa ihmisen antamat trigrammiestimaatit ovat jonkin verran pielessä ja tilastolliset pehmentämättömät trigrammiestimaatit aivan pielessä.
Tilastollisten estimaattien laskuun käytettiin n. 30 miljoonan sanan aineistoa. Tässä aineistossa ei yksikään annetuista taivutetuista trigrammeista esiintynyt kertaakaan. Trigrammit perusmuotoistamalla löydettiin 11 lausetta, joissa esiintyi ``tuntua jo hyvä''. Estimaatti kaipaa siis selvästi tasoittamista, eikä senkään jälkeen ole kovin luotettava.
Myös esimerkki-ihmisen antamaa estimaattia voi epäillä, aivan mahdollisille lauseille on annettu nollatodennäköisyys, esim. ``Kyllä alkaa tuntumaan jo kumisaapas jalassa'', lause joka voidaan tokaista vaikka pitkän vaelluksen päätteeksi. Toisaalta annetulla 2 desimaalin tarkkuudella estimaatit lienevät hyviä.
Kun testihenkilölle annettiin koko lause nähtäväksi, saatiin jo varsin laadukkaat estimaatit. Jotta tilastollisesti pystyttäisiin pääsemään samaan tulokseen, tarvitsisi mallin ymmärtää suomen kielen syntaksia (miten sanoja voidaan taivuttaa ja laittaa peräkkäin) sekä myös sanojen semanttista merkitystä (``helmikuu'' on lopputalvea, melkein kevättä).
- a)
- Suurimman uskottavuuden estimaatit voidaan laskea kaavasta
missä funktio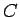 kertoo opetusjoukossa nähtyjen näytteiden määrän.
kertoo opetusjoukossa nähtyjen näytteiden määrän.
Unigrammiestimaatissa unohdetaan riippuvuus kaikista edellisistä sanoista, bigrammiestimaatti riippuu vain edellisestä sanasta ja trigrammiestimaatissa käytetään historiana kahta edellistä sanaa.
Unigrammiestimaatit voidaan siis laskea
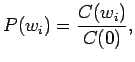
missä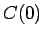 on opetusjoukon näytteiden lukumäärä. Estimaatit ovat
siis samat kummallekin tehtävänannon historialle.
on opetusjoukon näytteiden lukumäärä. Estimaatit ovat
siis samat kummallekin tehtävänannon historialle.
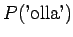
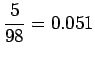
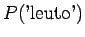
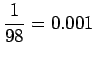
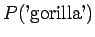
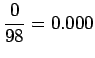
Bigrammiestimaatit saadaan ottamalla yksi sana historiasta käyttöön:
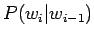
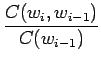
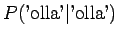
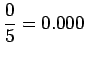
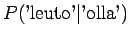
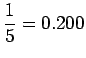
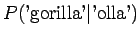
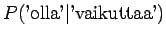
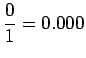
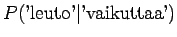
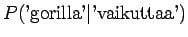
Huomataan, että tämän mallin mielestä mikään sanayhdistelmä, mitä se ei ole nähnyt ei ole mahdollinen. - b)
- Laplacen estimaatissa aikaisemmin havaitsemattomille
sanoille annetaan hieman todennäköisyyttä. Estimaatti vastaa
prioria, että kaikki sanat ovat yhtä todennäköisiä. Käytännössä se
lasketaan niin, että kuvitellaan että kaikkia sanoja on jo nähty
kerran:
missä on mallin sanaston koko.
on mallin sanaston koko.
Lasketaan siis estimaatit:
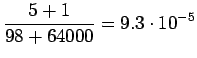
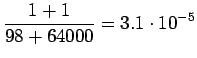
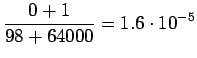
Bigrammeille:
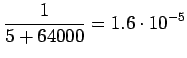
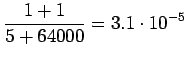
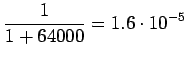
Huomataan, että tässä priorioletus, että kaikki sanat ovat yhtä todennäkisiä ohjaa estimaatteja vahvasti, kaikki sanat ovat toisaan mallien mielstä lähes yhtä todennäköisiä. - c)
- Lidstonen estimaatissa voidaan säätää sitä, kuinka paljon uskotaan
siihen, että sanat ovat yhtä todennäköisiä. Siinä kuvitellaan,
että sanat on jo nähty
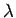 kertaa ennen opetusaineistoa:
kertaa ennen opetusaineistoa:
Valitaan tässä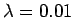 . Lasketaan estimaatit:
. Lasketaan estimaatit:
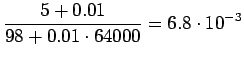
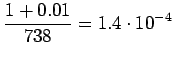
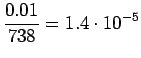
Bigrammeille:
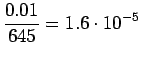
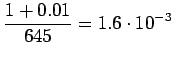
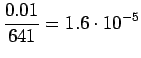
Tässä tapauksessa opetusdata ohjaa selkeämmin estimaatteja. Sopiva voidaan valita laittamalla
opetusjoukosta pieni osa sivuun ja testaamalla tällä sivuun
laitetulla tekstillä, mikä toimii parhaiten.
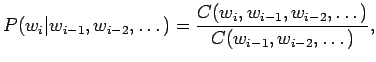
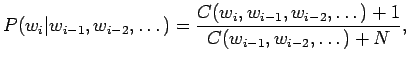
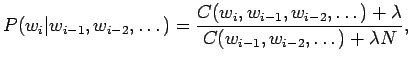
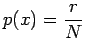
missä
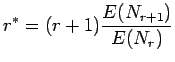 |
(2) |
Good-Turing -tasoitusta voi intuitiivisesti ajatella vaikka niin,
että kuvitellaan kaikkia yksiköitä nähdyksi hieman vähemmän kertoja
kuin ne oikeasti nähtiin. Eli jos trigrammi nähtiin 10 kertaa,
leikitään että se nähtiinkin vain 9.1 kerran. Jos trigrammi nähtiin
kerran, leikitään että se nähtiin 0.5 kertaa. Oletetaan että on
olemassa ![]() trigrammia, joita ei nähty ja leikitään, että ne nähtiin
0.3 kertaa. Tämä ei tietysti ole matemaattisiseti aivan eksakti
määritelmä, mutta helpottaa ehkä tehtävän seuraamista.
trigrammia, joita ei nähty ja leikitään, että ne nähtiin
0.3 kertaa. Tämä ei tietysti ole matemaattisiseti aivan eksakti
määritelmä, mutta helpottaa ehkä tehtävän seuraamista.
Good-Turing -tasoituksen laskeminen aloitetaan taulukoimalla, kuinka
monta kertaa eri trigrammia on nähty ![]() kertaa (esim. aineistossa oli
7462 trigrammia, jotka kaikki esiintyivät 10 kertaa). Tästä taulukosta
on piiretty kuvaaja 1.
kertaa (esim. aineistossa oli
7462 trigrammia, jotka kaikki esiintyivät 10 kertaa). Tästä taulukosta
on piiretty kuvaaja 1.
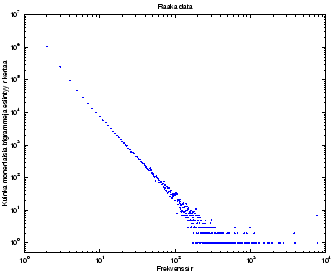
Huomataan, että tähän käyrään olisi helppo sijoittaa suora viiva,
paitsi että suuremmilla frekvensseillä tapahtuu jotain kummaa:
trigrammeja, joita on esiintynyt vaikkapa 500 kertaa on joko 0 tai 1
kappale. Eli lopussa ei ole enää tasaista käyrää, vaan vain
diskreettejä arvoja 0 ja 1. Kokeillaan tasoitella käyrän loppupäätä
levittämällä todennäköisyysmassaa tasaisesti koko ympäristöön. Esim.
jos trigrammi on esiintynyt 510 kertaa, mutta seuraavaksi yleisin
trigrammi on esiintynyt 514 kertaa, jaetaan tuo 1 koko välille, eli
kaikille frekvensseille 510-514 tulee arvoksi
![]() .
Katsotaan, miltä kuvaaja näyttää tämän jälkeen.
Kuvassa 2 nähdään tasoitettu data ja siihen sovitettu
suora. Suora sovitettiin kummankin muuttujan logaritmeihin, jolloin se
saatiin kauniisti myötäilemään datan muotoa.
.
Katsotaan, miltä kuvaaja näyttää tämän jälkeen.
Kuvassa 2 nähdään tasoitettu data ja siihen sovitettu
suora. Suora sovitettiin kummankin muuttujan logaritmeihin, jolloin se
saatiin kauniisti myötäilemään datan muotoa.
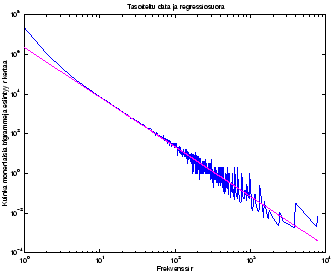
Matalat ![]() :n arvot ovat paremmin arvioidut koska niihin meillä on
ollu paljon dataa. Käytetään siis niiden arvioina suoraan taulukossa
olleita arvoja ja katsotaan korkeat
:n arvot ovat paremmin arvioidut koska niihin meillä on
ollu paljon dataa. Käytetään siis niiden arvioina suoraan taulukossa
olleita arvoja ja katsotaan korkeat ![]() :n arvot suoraan
käyrältä. Tässä tehtävässä päätin käyttää suoralta luettuja arvoja,
kun
:n arvot suoraan
käyrältä. Tässä tehtävässä päätin käyttää suoralta luettuja arvoja,
kun ![]() .
.
Vielä pitäisi antaa jonkinverran todennäköisyysmassa trigrammeille,
joita ei ole vielä nähty. Good-Turing estimaatissa näille annetaan
yhteensä
![]() todennäköisyyttä. Tämä todennäköisyys
voitaisiin jakaa vaikkapa aineistosta opetetulle bigrammimallille.
Nyt, jos trigrammimalli ei osaa antaa sanalle todennäköisyyttä,
voidaan tätä todennäköisyyttä kysyä bigrammimallilta. Tuntemattomille
bigrammeille jäävä todennäköisyysmassa voitaisiin taas puolestaan
jakaa unigrammimallille. Tuntemattomille unigrammeille jäävästä
todennäköisyydestä voidaan vain todeta, että tässä on todennäköisyys,
että tulee vastaan sana, jota malli ei tunne. Tällainen perääntyvä
(back-off) kielimalli on käytössä esim. lähes kaikissa suuren sanaston
puheentunnistimissa. Tässä esitettiin vain perusidea perääntyvien
kielimallejen estimoinnille. Käytännössä se ei ole aivan näin
suoraviivaista.
todennäköisyyttä. Tämä todennäköisyys
voitaisiin jakaa vaikkapa aineistosta opetetulle bigrammimallille.
Nyt, jos trigrammimalli ei osaa antaa sanalle todennäköisyyttä,
voidaan tätä todennäköisyyttä kysyä bigrammimallilta. Tuntemattomille
bigrammeille jäävä todennäköisyysmassa voitaisiin taas puolestaan
jakaa unigrammimallille. Tuntemattomille unigrammeille jäävästä
todennäköisyydestä voidaan vain todeta, että tässä on todennäköisyys,
että tulee vastaan sana, jota malli ei tunne. Tällainen perääntyvä
(back-off) kielimalli on käytössä esim. lähes kaikissa suuren sanaston
puheentunnistimissa. Tässä esitettiin vain perusidea perääntyvien
kielimallejen estimoinnille. Käytännössä se ei ole aivan näin
suoraviivaista.
Kun nyt laskemme korjatulla ![]() :llä kaavan 1 mukaan
todennäköisyydet saamme melko hyvät estimaatit eri sanojen
todennäköisyyksille. Taulukkoon 2 on merkitty
muutamalle eri r:lle todennäköisyydet. Opetetun mallin mielestä 81%
todennäköisyydestä on tuntemattomilla trigrammeilla. Tämä on suomen
kielelle melko uskottavan kuuloinen tulos, sillä suomen kielen
sanamäärä on niin suuri, että kielelle on käytännössä mahdotonta tehdä
kattavaa trigrammimallia. Sivuhuomatuksena mainittakoon, että
trigrammimallinnus voi soveltaa suomen kieleen myös hajoittamalla
sanat vaikkapa morfeemeiksi ja opettamalla trigrammimalli näiden
pienempien palojen yli.
:llä kaavan 1 mukaan
todennäköisyydet saamme melko hyvät estimaatit eri sanojen
todennäköisyyksille. Taulukkoon 2 on merkitty
muutamalle eri r:lle todennäköisyydet. Opetetun mallin mielestä 81%
todennäköisyydestä on tuntemattomilla trigrammeilla. Tämä on suomen
kielelle melko uskottavan kuuloinen tulos, sillä suomen kielen
sanamäärä on niin suuri, että kielelle on käytännössä mahdotonta tehdä
kattavaa trigrammimallia. Sivuhuomatuksena mainittakoon, että
trigrammimallinnus voi soveltaa suomen kieleen myös hajoittamalla
sanat vaikkapa morfeemeiksi ja opettamalla trigrammimalli näiden
pienempien palojen yli.
Huomautettakoon vielä, että tässä estimoitiin todennäköisyys
![]() sille, että aineistossa tulee vastaan
trigrammi
sille, että aineistossa tulee vastaan
trigrammi
![]() . Itse kielimallissahan
tarvitaan todennäköisyyksiä
. Itse kielimallissahan
tarvitaan todennäköisyyksiä
![]() , jotka saadaan
tässä estimoiduista arvoista laskettua.
, jotka saadaan
tässä estimoiduista arvoista laskettua.
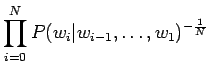 |
|||
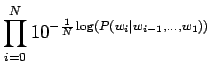 |
|||
Lasketaan summa erikseen:
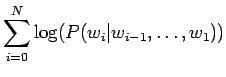 |
|||
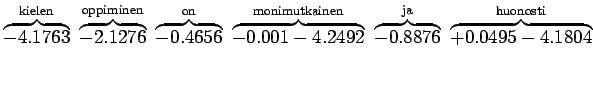 |
|||
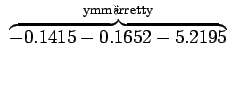 |
|||
Niille sanoille, joille ei löytynyt trigrammimallia, jouduttiin käyttämään sekä perääntymiskerrointa että todennäköisyyttä. Jos myöskään bigrammimallia ei löytynyt, jouduttiin vielä kerran perääntymään.
Sijoitetaan vielä luvut hämmentyneisyyden lausekkeeseen
Tulosta voi ajatella vaikka niin, että kielimalli vastaa sellaista kielimallia, joka joutuu valitsemaan 1200 yhtä todennäköisen sanan väliltä (ei ihan eksaktisti paikkansapitävä väite).
Sana 'tapahtumaketju' ei ollut 64000 yleisimmän sanan joukossa ja ei
sisältynyt siis kielimalliin. Kielimallin ohi meni siis
![]() sanoista.
sanoista.