- Frekvenssimenetelmä: Bigrammeja ``valkoinen'',''talo'' oli
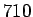 kappaletta.
kappaletta.
- Normalisoitu frekvenssimenetelmä: Sana ``valkoinen'' esiintyi
3665 kertaa ja sana ``talo'' 10767 kertaa. Vertailuluvuksi saadaan
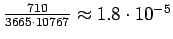 .
.
|
|
|
Normalisoitu frekvenssi
|
| liukas | keli | 1981 |
| aste | pakkanen | 386 |
| heittää | veivi | 293 |
| herne | nenä | 268 |
| valkoinen | talo | 180 |
| tuntematon | sotilas | 163 |
| vihainen | mielenosoittaja | 68 |
| kova | tuuli | 35 |
| ottaa | onki | 21 |
| venäjä | presidentti | 10 |
| oppia | lukea | 8 |
| hakea | työ | 1 |
| olla | ula | 0 |
| sekä | myös | 0 |
| ja | olla | 0 |
Huomataan, että jo ``hihasta ravistetuilla'' menetelmillä päästään kohtalaisiin tuloksiin.
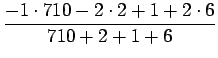
Varianssi
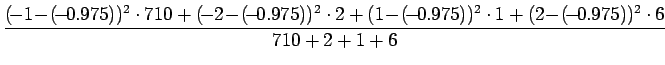
Lopuille sanoille tulokset on annettu varianssin mukaan järjestettynä taulukossa 3.
|
|
|
Keskiarvo | Varianssi |
| herne | nenä | -1.000 | 0.000 |
| vihainen | mielenosoittaja | -1.000 | 0.000 |
| tuntematon | sotilas | -1.025 | 0.025 |
| valkoinen | talo | -0.975 | 0.083 |
| ottaa | onki | -1.250 | 0.188 |
| venäjä | presidentti | -1.128 | 0.472 |
| kova | tuuli | -0.880 | 0.492 |
| liukas | keli | -0.788 | 0.608 |
| oppia | lukea | -0.606 | 1.087 |
| heittää | veivi | -0.500 | 1.250 |
| aste | pakkanen | -0.465 | 1.347 |
| hakea | työ | -0.433 | 2.046 |
| olla | ula | -0.250 | 2.438 |
| sekä | myös | 0.252 | 2.981 |
| ja | olla | -0.083 | 3.635 |
Taulukkoa tarkastellessamme huomaamme, että menetelmä on löytänyt käytännössä kaikki kiinteät kollokaatiot, kuten valkoinen talo. Menetelmä ei pärjää hyvin harvalla aineistolla, esim. vihainen mielenosoittaja ei selvästikään ole kollokaatio, vaikka menetelmä sen toiseksi sijoittaakin.
Tarkasteluikkunan leveys vaikuttaa tietysti alueeseen, josta kollokaatioita etsitään. Jos aluetta kasvatetaan liian suureksi, rupeavat sanat esiintymään yhä useammin myös satunnaisesti yhdessä ja varianssi kasvaa suureksi. Liian pienellä ikkunalla ei pitempivaikutteisia kollokaatioita löydetä. Jos kollokaation toinen sana voi olla sekä referenssisanan edessä että takana, menetelmä tietysti hämääntyy täydellisesti.
Aloitetaan kasaamalla
seuraavanlainen taulukon (taulukko 4):
Nämä arvot voidaan sijoittaa sitten kahden muuttujan
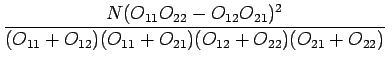
Luvut sijoittamalla saadaan siis:
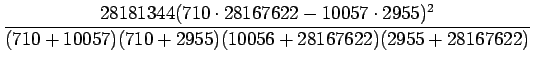
Jos
|
|
|
|
| liukas | keli | 591591 |
| valkoinen | talo | 358771 |
| aste | pakkanen | 173726 |
| tuntematon | sotilas | 70409 |
| ja | olla | 29194 |
| kova | tuuli | 26644 |
| venäjä | presidentti | 18147 |
| heittää | veivi | 4120 |
| herne | nenä | 2258 |
| vihainen | mielenosoittaja | 1321 |
| ottaa | onki | 525 |
| oppia | lukea | 449 |
| hakea | työ | 47 |
| sekä | myös | 45 |
| olla | ula | 0 |
Viimeksi pyydettiin vielä laskemaan uskottavuussuhdetestillä järjestys sanoille. Uskottavuussuhdetestissä tarkastellaan kahden eri hypoteesin uskottavuuden suhdetta:
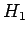 :
:- sanat esiintyvät satunnaisesti toisistaan riippumatta
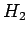 :
:- sanojen esiintyminen riippuu toisistaan
Uskottavuussuhdetestin laskemiseen tarvitaan seuraavia suureita (luvut
ovat tehtävän sanoille ``valkoinen'' ja ``talo''):
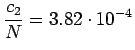
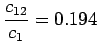
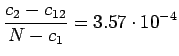
Jos oletetaan sanoille binomijakauma
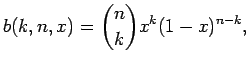 |
voidaan uskottavuuksien suhde kirjoittaa (tarkempi johto kirjassa, katso myös sieltä lainattu taulukko 6)
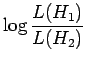 |
|||
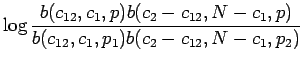 |
Tässähän lasketaan kullekin hypoteesille datan uskottavuus kahdessa osassa. Ensin lasketaan todennäköisyys niille bigrammeille, joissa ensimmäinen sana on ``valkoinen'' (näistä
Sievennellään
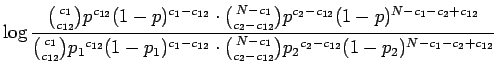 |
|||
Sijoittamalla yhtälöissä 1-7 annetut arvot käyttäen luonnollisia logaritmeja saadaan tulokseksi -3811.
Kun katsomme uskottavuussuhdetestin tuloksia (taulukko 7),
huomaamme että myös tässä testi ei testaa sitä, ovatko sanat
kollokaatioita, vaan sitä ovatko ne riippumattomia. Tuloksia voidaan
perustella samoin argumentein kuin ![]() testin kohdalla.
testin kohdalla.
|
|
|
|
| ja | olla | -21567 |
| valkoinen | talo | -3811 |
| venäjä | presidentti | -1696 |
| kova | tuuli | -1013 |
| aste | pakkanen | -972 |
| liukas | keli | -824 |
| tuntematon | sotilas | -799 |
| oppia | lukea | -46 |
| vihainen | mielenosoittaja | -30 |
| heittää | veivi | -29 |
| ottaa | onki | -28 |
| sekä | myös | -26 |
| herne | nenä | -17 |
| hakea | työ | -15 |
| olla | ula | 0 |
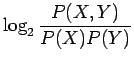
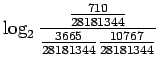
Tulokset koko sanajoukolle on esitetty taulukossa 8.
|
|
|
MI |
| liukas | keli | 12.4 |
| aste | pakkanen | 10.1 |
| heittää | veivi | 9.7 |
| herne | nenä | 9.6 |
| valkoinen | talo | 9.0 |
| tuntematon | sotilas | 8.8 |
| vihainen | mielenosoittaja | 7.6 |
| kova | tuuli | 6.6 |
| ottaa | onki | 5.9 |
| venäjä | presidentti | 4.8 |
| oppia | lukea | 4.5 |
| hakea | työ | 1.7 |
| olla | ula | 0.5 |
| sekä | myös | -0.8 |
| ja | olla | -2.5 |
Tulokset vaikuttavat hyviltä. Hieman kommenttia kirjan kritikkiin, että menetelmä erityisesti suosisi harvinaisia sanoja: Yksi tekijä joka tähän johtaa, on laskussa käytettyjen todennäköisyyksien estimointi - tässä käytetään maksimiuskottavuusestimaattoreita. Paremman tuloksen saa varmasti, jos asettaa sanapareille priorin, että ne ovat riippumattomia ja antaa datan sitten muokata tätä oletusta.