 |
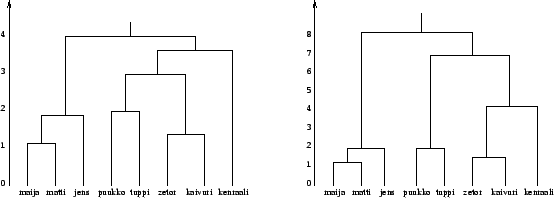
Piirretään vielä klusterointeja vastaavat dendrogammit. Dendrogrammissa on pystysuunnassa etäisyysasteikko, ja aina kun kaksi ryhmää yhdistetään, se merkitään tälle etäisyydelle (Kuva 2).
Nyt kun haluamme muodostaa klusterit, meidän pitäisi vielä
dendrogrammista osata päätellä, mikä etäisyys laitetaan
raja-arvoksi klustereiden muodostumiselle. Nyt vaikuttaisi siltä,
että sekä single link, että complete link -klusteroinnille sopiva
raja-arvo olisi noin 2.9. Tämän rajan alapuolella molemmat
menetelmät antavat saman klusteroinnin (Taulukko 1).
- 1)
- Päätetään kuinka monta klusteria halutaan löytää
- 2)
- Sijoitetaan alkuperäiset klusterikeskukset jollain tavalla avaruuteen (esim. arpomalla järkevälle alueelle datapilven sisään)
- 3)
- Merkitään kaikille datapisteille, mikä klusterikeskus on sitä lähinnä
- 4)
- Siirretään klusterikeskusta: lasketaan niiden näytteiden paikan keskiarvo, joille klusterikeskus on lähin ja siirretään klusterikeskus sinne
- 5)
- Tarkistetaan, täyttyikö lopetusehto (esim. klusterointi ei muuttunut). Jos ei, palataan askeleeseen 3.
Tässä tehtävässä siis etsitään kolmea klusteria, klustereiden alustava sijainti on annettu. Kuvassa 3 esitetään algoritmin kulku.
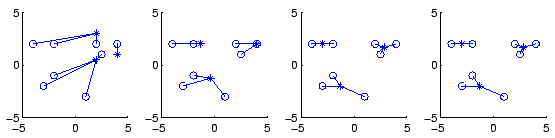 |
Tässä saatiin siis taulukossa 2 nähtävät
klusterit.
|
- a)
- Kuvaan 4 on piirretty annettu
data. Knn-tunnistimen naapureiden määräksi valittiin 3. Tämä
tarkoittaa sitä, että etsitään kunkin luokiteltavan sanan kolme
lähintä naapuria ja nämä äänestävät siitä, mihin luokkaan sana
laitetaan.
Kuva: Data. Verbit on merkitty laatikoilla, substantiivit ympyröillä ja luokiteltavat sanat tähdellä. 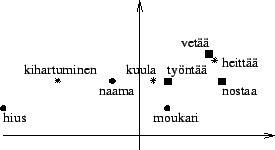
Katsotaanpa ensinnä sanaa kihartuminen. Sen kolme lähintä tunnettu naapuria ovat hius, naama ja työntää. Vastaavat äänet ovat S,S ja V eli sana luokitellaan substantiiviksi.
Sanalle kuula lähimmät naapurit ovat työntää, moukari ja naama. Näin ollen se luokitellaan substantiiviksi.
Sana heittää naapurit vetää, nostaa ja työntää ovat yksimielisiä siitä, että sana on verbi.
- b)
- Korvataan kukin luokka sen keskipisteellä. Verbien
keskipiste on
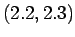 ja substantiiveille se on
ja substantiiveille se on
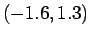 .
Nyt sanaa heittää lähinnä on verbien keskipiste, sanaa
kihartuminen substantiivejen ja sanaa kuula
lähinnä verbien keskipiste.
.
Nyt sanaa heittää lähinnä on verbien keskipiste, sanaa
kihartuminen substantiivejen ja sanaa kuula
lähinnä verbien keskipiste.
- c)
- b-kohdan menetelmässä korvataan yksittäiset datapisteet
niitä kaikkia yhteiseti edustavalla prototyypillä. Tämä vähentää
tuntuvasti luokittelussa tarvittavien laskutoimitusten määrää (sen
sijaan että luokiteltavan sana etäisyys pitää laskee kaikille
sanoille, riittää että se lasketaan keskiarvoille). Joissain
tapauksissa tällainen prototyyppimalli myös yleistää paremmin.
Tässä tapauksessa nähdään menetelmän huono puoli: Se ei pysty esittämään monimutkaisemman datapilven muotoa yhtä hyvin kuin siinä olevat datapisteen erikseen lueteltuna ja tässä luokittelee sanan kuula väärin.
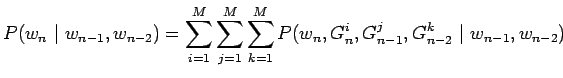 |
Tässä siis
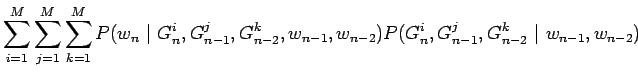 |
Sievennetään ensimmäistä termiä olettamalla että sana
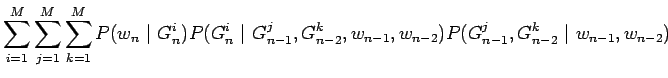 |
Nyt voimme sieventää toista termiä olettamalla, että nykyinen ryhmä
![]() riippuu vain edeltävistä ryhmistä, mutta ei edeltävistä
sanoista. Jaetaan viimeinen termi vielä tutulla tavalla osiin.
riippuu vain edeltävistä ryhmistä, mutta ei edeltävistä
sanoista. Jaetaan viimeinen termi vielä tutulla tavalla osiin.
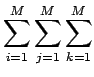 |
|||
Koska sana voi kuulua vain yhteen ryhmään, riippuu todennäköisyys
![]() vain sanasta
vain sanasta ![]() ja
on yksi, kun on kyseessä ryhmä, johon sana kuuluu.
ja
on yksi, kun on kyseessä ryhmä, johon sana kuuluu.
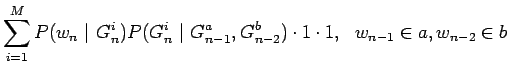 |
Koska
Tämä sievennetyn lausekkeen voisi ilmaista viellä hieman
yksinkertaisemmin merkitsemällä ![]() :llä ryhmää, johon sana
:llä ryhmää, johon sana
![]() kuuluu:
kuuluu:
Mietitäänpä vielä lopuksi, mitä tällaisella approksimaatiolla
saadaan aikaiseksi. Oletetaanpa vaikka, että meillä on 64000
sanasto, joista olemme muodostaneet 1000 klusteria. Nyt
arvioitavien parametrien määrä on pudonnut
![]() :sta
:sta
![]() :ään. Jos
oletetaan, että sanat on hyvin klusteroitu ja klusterien väliset
siirtymät kuvaavat lähes yhtä hyvin kuin sanojen väliset siirtymät,
saadaan nämä parametrit myös arvioitua paljon paremmin kuin
trigrammimallin parametrit (enemmän dataa per parametri). Jos
klusterointi puolestaan on huono, eikä klusterista toiseen
siirtyminen juurikaan vastaa sanoista toiseen siirtymistä, malli
arvio vähäiset parametrinsa huonosti ja on todennäköisesti paljon
heikompi malli kuin trigrammimalli. Edelleenkin tietysti parametrien
määrä on paljon pienempi.
:ään. Jos
oletetaan, että sanat on hyvin klusteroitu ja klusterien väliset
siirtymät kuvaavat lähes yhtä hyvin kuin sanojen väliset siirtymät,
saadaan nämä parametrit myös arvioitua paljon paremmin kuin
trigrammimallin parametrit (enemmän dataa per parametri). Jos
klusterointi puolestaan on huono, eikä klusterista toiseen
siirtyminen juurikaan vastaa sanoista toiseen siirtymistä, malli
arvio vähäiset parametrinsa huonosti ja on todennäköisesti paljon
heikompi malli kuin trigrammimalli. Edelleenkin tietysti parametrien
määrä on paljon pienempi.
Käytetään kirjassa esitettyä mallia todennäköisyydelle
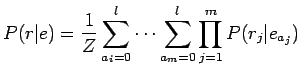 |
missä
Tässä siis kokeillaan kaikkia käännössääntöjä jokaiselle ruotsinkielisen lauseen sanalle (huomioimatta sanajärjestystä). Koska säännöstö on hyvin harva, päästään näin yksinkertaiseen laskutoimitukseen.
Prioritodennäköisyys ![]() saadaan kielimallista. Lasketaan se
kummallekin lauseelle:
saadaan kielimallista. Lasketaan se
kummallekin lauseelle:
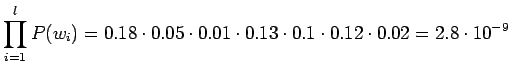 |
|||
Kertomalla priori ja käännöstodennäköisyys huomataan, että
jälkimmäinen käännös on todennäköisempi:
Huomattavaa on, että käännösmalli ei ota mitään kantaa sanajärjestykseen. Koska myöskään kielimalli (unigrammimalli) ei tätä tee, mallin mielestä sanajärjestyksellä ei ole mitään merkitystä. Jos mallilta kysytään todennäköisintä lausettta (ei testata eri vaihtoehtoja) huomataan, että todennäköisimpään lauseeseen ei voi tulla artikkeleja eikä sanaa ``into''. Tämä johtuu siitä, että niiden lisääminen ei muuta käännöstodennäköisyyttä, mutta tiputtaa aina kielimallitodennäköisyyttä. Kielimalli siis suosii muutenkin lyhyempiä lauseita. Kasvattamalla kielimallin konteksti trigrammiksi, saisi ehkä artikkelit ja sanajärjestyksen paremmin kohdalleen.
Yleisesti tällä menetelmällä tarvitaan heuristiikkaa valitsemaan käännökset, joita tutkitaan. Kaikkien vaihtoehtojen läpikäynti on käytännössä mahdotonta.