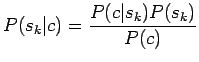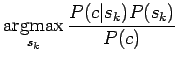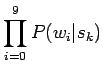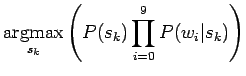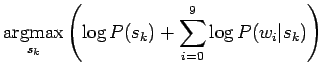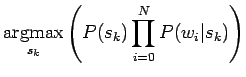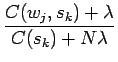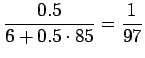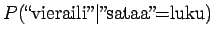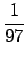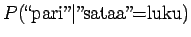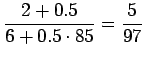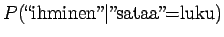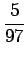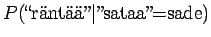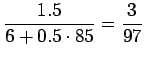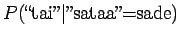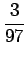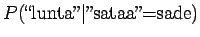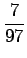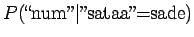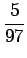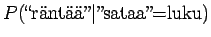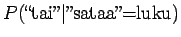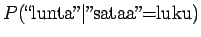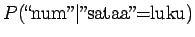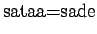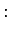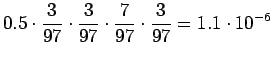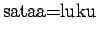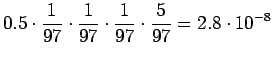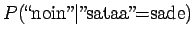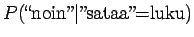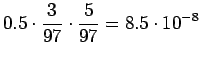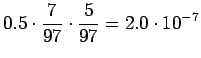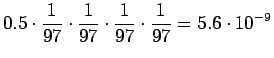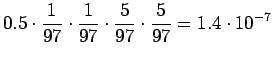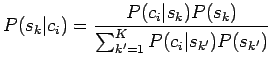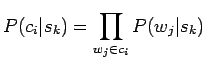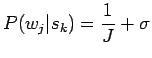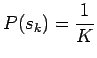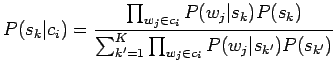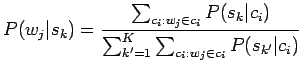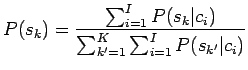T-61.281 Luonnollisten kielten tilastollinen käsittely
Vastaukset 10, ti 4.1.2003, 16:15-18:00 - Sanojen
merkitysten erottelu, Versio 1.0
- 1.
- Aloitetaan Bayesin kaavasta:
Nyt meitä kiinnostaa vain todennäköisyyksien järjestys, eikä
absoluuttinen arvo, joten voimme unohtaa normalisointitekijän 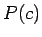 :
:
Yhtälössä jälkimmäinen termi on sanan merkityksen
prioritodennäköisyys, joka voidaan estimoida esimerkiksi laskemalla
kuinka suuri osa opetusjoukon sanoista on esiintynyt merkityksessä
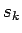 . Keskitytään tässä tarkastelemaan termiä
. Keskitytään tässä tarkastelemaan termiä 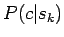 .
.
Kontekstiksi valitaan vaikkapa sanaa ympäröivät 10 sanaa:
Tässä siis sana, jonka merkitystä arvioidaan olisi  merkintöjen helpottamiseksi. Tässä siis sanojen järjestyksellä on
väliä, sitä voidaan merkitä laittamalla sanat kaarisulkuihin.
Tällaisilla piirrevektoreilla tunnistimen opettaminen on käytännössä
mahdotonta, koska kahta täysin samaa 10 sanan kontekstia tuskin
löytyy opetus- ja testijoukosta. Approksimoidaan tätä mallia
olettamalle, että sanojen järjestyksellä ei ole
väliä (aaltosulut):
merkintöjen helpottamiseksi. Tässä siis sanojen järjestyksellä on
väliä, sitä voidaan merkitä laittamalla sanat kaarisulkuihin.
Tällaisilla piirrevektoreilla tunnistimen opettaminen on käytännössä
mahdotonta, koska kahta täysin samaa 10 sanan kontekstia tuskin
löytyy opetus- ja testijoukosta. Approksimoidaan tätä mallia
olettamalle, että sanojen järjestyksellä ei ole
väliä (aaltosulut):
Nyt meillä on siis:
Helpotetaan todennäköisyysjakauman estimointia ja oletetaan että sanat
esiintyvät toisistaan riippumatta:
Kirjoitetaan vielä kaava auki
Viimeisellä rivillä kaava on kirjoitettu logaritmimuotoon.
Tämähän voitiin tehdä, koska logaritmin otto ei vaihda lukujen
suuruusjärjestystä. Riippuu tilanteesta onko suora vai logaritminen
muoto kätevämpi.
Huomataan, että mikään matkan varrella tehdyistä approksimaatioista ei
ole täysin oikein, karkein virhe tehdää ehkä arvioidessa kontekstin
sanat riippumattomiksi. Näin saadaan kuitenkin käyttökelpoinen menetelmä.
- 2.
- Käytetään edellisessä tehtävässä johdettua Naivin Bayestunnistimen kaavaa:
missä 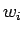 on konteksissa esiintyneet sanat.
on konteksissa esiintyneet sanat.
Tarvitsemme laskun suorittamiseen kahta estimaattia, todennäköisyyttä
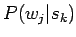 että kontekstin sana
että kontekstin sana 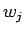 esiintyy merkityksen
kanssa ja merkityksen prioritodennäköisyyttä
esiintyy merkityksen
kanssa ja merkityksen prioritodennäköisyyttä 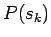 .
Koska näytejoukossamme on yhtä monta esintymää
merkitykselle sataa=sade ja sataa=luku, voimme
ainoastaan asettaa prioritodennäköisyydeksi
.
Koska näytejoukossamme on yhtä monta esintymää
merkitykselle sataa=sade ja sataa=luku, voimme
ainoastaan asettaa prioritodennäköisyydeksi 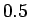 .
Kirjan laskuissa sovelletaan järjestään ML-estimointia (suurimman
uskottavuuden estimointi). Tehtävässä kuitenkin pyydettiin käyttämään
prioreita, joten määritellään
todennäköisyydelle
pieni priori, että kaikki sanat ovat
yhtä todennäköisiä kaikissa konteksteissa ja lisätään seuraaviin
estimaatoreihin
.
Kirjan laskuissa sovelletaan järjestään ML-estimointia (suurimman
uskottavuuden estimointi). Tehtävässä kuitenkin pyydettiin käyttämään
prioreita, joten määritellään
todennäköisyydelle
pieni priori, että kaikki sanat ovat
yhtä todennäköisiä kaikissa konteksteissa ja lisätään seuraaviin
estimaatoreihin
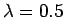 . Suuremman
. Suuremman 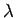 :n valinnalla
voidaan korostaa prioriuskon merkitystä ja vähäinen todistus
opetusjoukossa ei vielä suuremmin hetkauta tuota uskomusta. Tätä tapaa
kutsutaan MAP (Maksimi A Posteriori) -estimoinniksi. Se voidaan
ajatella vaikka niin, että kuvitellaan jo etukäteen nähdyksi
opetusjoukon, jossa jokainen tunnettu sana on esiintynyt 0.5 kertaa
molemmissa konteksteissa.
:n valinnalla
voidaan korostaa prioriuskon merkitystä ja vähäinen todistus
opetusjoukossa ei vielä suuremmin hetkauta tuota uskomusta. Tätä tapaa
kutsutaan MAP (Maksimi A Posteriori) -estimoinniksi. Se voidaan
ajatella vaikka niin, että kuvitellaan jo etukäteen nähdyksi
opetusjoukon, jossa jokainen tunnettu sana on esiintynyt 0.5 kertaa
molemmissa konteksteissa.
Tässä tunnettujen sanojen lukumäärä 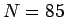 .
.
- a)
- Lasketaan ensimmäisen lauseen merkityksen luokitteluun
tarvittavat estimaattorit:
Huomataan, että ensimmäiseen merkitykseen ei saada kuin priorin
aiheuttamaan todennäköisyysmassaa. Vertailuluvuksi
(normalisoimattomaksi todennäköisyydeksi) saadaan
Lasketaanpa sama merkitykselle sataa=luku:
Vertailuluvuksi saadaan
Mallin mukaan merkitys sata=luku on siis todennäköisempi.
- b)
- Kuten edellä lasketusta huomaamme, voimme jättää sanat,
joita ei ole havaittu kummankaan sanan kontekstissa huomiotta, sillä
ne eivät vaikuta vertailulukujen järjestykseen, vain ainoastaan
niiden suuruuteen. Käytetään muunninta, joka muuntaa numerot muotoon
``num'' (tässä tapauksessa kolmantena=''num''). Lasketaan siis 2.
kohdassa todennäköisyydet ainoastaan seuraaville:
Vertailuluvuiksi saadaan
Eli nyt ilmeisesti sana tarkoittaa sadetta.
- c)
- Kolmannelle lauseelle saadan
Vertailuluvuiksi saadaan
Eli nyt ilmeisesti sana tarkoittaa lukua.
- d)
- Viimeisen lauseen sanojen todennäköisyyksiä ei annettu
opetusdata muokaa mihinkään suuntaan ja koska priorien mukaan
molemmat merkitykset ovat yhtä todennäköisiä, ei malli pysty
tekemään mitään päätöstä tässä tilanteessa.
- 3.
- Etsitään kaikille lauseen sanoille sanakirjamääritelmät. Verrataan
näitä sanakirjamääritelmiä haettavan sanan kummankin merkityksen
sanakirjamääritelmään. Kumman merkityksen selityksessä on enemmän
yhteisiä sanoja lauseen sanojen selitysten kanssa paljastaa, kumpi
merkitys on oikea.
Tässä tapauksessa ampumista tarkoittavan merkityksen selostuksesta
löytyy sanat ``harjoitella'' ja ``varusmies'', jotka löytyvät suoraan
annetusta lauseesta. Sana ``sarjatuli'' löytyy sanan ``kivääri''
selityksestä, joten ampumista tarkoittavalle merkitykselle 3 pistettä.
Lehmän ammunta tarkoittavan merkityksen selostuksesta löytyy sana
``niityllä'', joka löytyy myös suoraan lauseesta. Tälle merkitykselle
1 piste.
Ilmeisesti siis nyt on kyseessä ampuminen (3>1).
Sivuhuomautus: Vaikka kirjan menetelmissä käytetään runsaasti sanaa
Bayes, mitkään estimaatit siellä eivät ole Bayesiläisiä vaan
perinteisiä maksimiuskottavuusestimaatteja.
- 4.
- Katsotaanpa, kuinka monta osumaa google antaa.
| prices |
go up |
21400 |
| price |
goes up |
18900 |
| |
|
40300 |
| |
|
|
| prices |
slant |
2 |
| prices |
lean |
56 |
| prices |
lurch |
7 |
| price |
slants |
0 |
| price |
leans |
24 |
| price |
lurches |
2 |
| |
|
91 |
Tämän äänestyksen voittaa selvästi kallistua sanan merkitys
``go up'', nousta.
Entäpä toinen esimerkkimme? Jos teemme käännöksen ja haun noudattaen
annettua sanajärjestystä, emme saa yhtään osumaa. Kokeillaan siis
etsiä dokumenttejä, joissa esiintyy sanat missä tahansa
järjestyksessä:
| want |
shin |
hoof |
liver |
or |
snout |
26 |
| like |
shin |
hoof |
liver |
or |
snout |
29 |
| covet |
shin |
hoof |
liver |
or |
snout |
26 |
| desire |
shin |
hoof |
liver |
or |
snout |
23 |
| |
|
|
|
|
|
104 |
| |
|
|
|
|
|
|
| want |
kick |
poke |
cost |
or |
suffer |
1590 |
Huomataan, että sanojen verbimerkitykset voittavat tässä, vaikkakin
tämä merkitys on ilmeisesti väärä. Kaikkia hakuja ei tarvitse edes
suorittaa, koska jo ensimmäinen haku tuottaa enemmän osumia kuin toisten
merkitysten haut yhteensä. Lisäksi suurin osa ensimmäisen 4
haun palauttamista osumista oli sanakirjoja. Huomataan, että koska
merkitykset shin, hoof, liver ja snout ovat paljon
harvinaisempia kuin verbimuodot, niitä myös löytyy suhteessa paljon
vähemmän. Tässä tilanteessa pitäisi hakua varmaankin normalisoida
jollain tavoin. Hakua vaikeuttaa myös se, että annettu lause ei ole
kiinteä ilmaisu, kuten ensimmäisessä kohdassa.
- 5.
- Tehtävässä pitäisi siis arvioida merkityksen todennäköisyys, kun
tiedetään konteksti
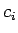 .
.
Käytetään aikaisemmin esitetty naivin
Bayesluokittiemen oletusta, että kontekstin sanat eivät riipu
toisistaan:
Alustetaan EM-algoritmissa tarvittavat suureet:
- Asetetaan kaikki sanat yhtä todennäköisiksi kummallekin
lähteelle ja lisätään tasajakaumaan hieman kohinaa
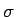 . Ilman kohinaa
algoritmi ei tule konvergoimaan, koska kaikki tapahtumat ovat yhtä
todennäköisiä.
. Ilman kohinaa
algoritmi ei tule konvergoimaan, koska kaikki tapahtumat ovat yhtä
todennäköisiä.
Tässä 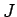 on tunnettujen sanojen määrä.
on tunnettujen sanojen määrä.
- Asetetaan kaikki merkitykset yhtä todennäköiksi
Tässä 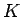 on erilaisten merkitysten määrä.
on erilaisten merkitysten määrä.
- Lasketaan kunkin merkityksen todennäköisyys kaikille
konteksteille:
- Arvioidaan uudet sanatodennäköisyydet E-askeleessa arvioitujen
lausetodennäköisyyksien avulla:
- Päivitetään prioritodennäköisyydet:
Kuva:
EM algoritmi. Kuva esittää algoritmin konvergoitumisen.
Sanat oikealta vasemmalle lueteltuna: yksi, kaksi, kolme, neljä,
viisi, seitsemän, kahdeksan, mänty, leppä, haapa, koivu, kataja.
Lauseet ovat samassa järjestyksessä kuin kysymyksessä.
![\begin{figure}\centering\mbox{\subfigure[$P(w_j\vert s_0)$: Todennäköisyys, että...
...merkityksessä $s_0$]{\epsfig{figure=sp.eps,width=0.45\linewidth}}}
\end{figure}](img79.gif) |
Kuvassa 1 on esitetty algorimin konvergointi, kun E- ja
M-askelta iteroidaan vuorotellen. Tässä tapauksessa
prioritodennäköisyydet pidettiin 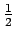 :ssa ensimmäiset 15
iteraatiota, mikä paransi algoritmin stabiilisuutta. Huomataan, että
algoritmi kykenee pomimaan numerot ja puulajit erilleen. Lauseille 8
ja 9 malli ylioppii ja sijoittaa ne varmasti jompaan kumpaa
merkitykseen. Datan määrän kasvaessa nämäkin estimaatit varmaan
asettuisivat paremmin kohdalleen.
:ssa ensimmäiset 15
iteraatiota, mikä paransi algoritmin stabiilisuutta. Huomataan, että
algoritmi kykenee pomimaan numerot ja puulajit erilleen. Lauseille 8
ja 9 malli ylioppii ja sijoittaa ne varmasti jompaan kumpaa
merkitykseen. Datan määrän kasvaessa nämäkin estimaatit varmaan
asettuisivat paremmin kohdalleen.
Käytännössä aivan samaa algorimia voidaan käyttää jakamaan
dokumenttikokoelma eri aihepiireihin. Silloin kontekstina on koko
dokumentti.
[6.]
Tehtävän ratkaisu vaihe vaiheelta. Tärkeimmät kohdat, jossa on tehty
mielivaltainen päätös, jonka voi aiheuttaa epätarkkuutta menetelmään
ja jonka voisi helposti tehdä toisin on merkitty kursiivilla.
- 1)
- Ensimmäinen tehtävä on siivota datasta kaikki ylimääräiset
otsikot, tägit ja merkit pois. Sitten haluamme erottaa lauseet
erilleen. Pidetään kunkin sanan konteksina koko lausetta, missä se
esiintyy. Muutetaan jotkut kaksi sanaa yhdeksi sanaksi,
esim. sanat ``sade'' ja ``komissio''. Merkitään myös muistiin
oikeat vastaukset, vaikka ei käytetäkään niitä opetuksessa.
- 2)
- Muutetaan kaikkien kontekstien sanat vektorimuotoon. Tässä
voitaisiin käyttää binäärisiä indikaattorivektoreita, mutta
approksimoidaan niitä asettamalla joka sanalla satunnainen,
yhden pituinen 200-ulotteinen vektori. Jos vektori on tarpeeksi
suuriulotteinen, se on suurinpiirtein ortogonaalinen kaikkien muiden
sanavektoreiden kanssa ja approksimaatio ei aiheuta suurta virhettä.
- 3)
- Oletetaan, että kontekstin sanojen järjestys ei
vaikuta. Lasketaan kunkin sanan konteksti summaamalla
sitä ympäröivien sanojen vektorit yhteen ja jakamalla summa
kontekstin sanojen määrällä.
- 4)
- Klusteroidaan kontekstivektorit, tässä
SOM-algoritmilla. Päätetään sopiva klustereiden määrä
kokeilemalla. Pienestä määrästä klustereita voi nopeammin
silmämääräisesti arvioida menetelmän onnistumista, iso määrä
klustereita voi antaa hienojakoisemman erottelun.
- 5)
- Nyt pitäisi arvioida annetun klusteroinnin hyvyys.
Ohjaamattomilla menetelmillä tämä on joskus hieman hankalaa, mutta
tässä tapauksessa voidaan menetellä seuraavasti: Katsotaan
ensin opetusjoukolla, menivätkö erimerkityksiset sanat siististi eri
klustereihin. Tämähän ei sinänsä vielä todista paljoa, jos valitaan
yhtä monta klusteria kuin opetusjoukon sanoja, saadaan
automaattisesti täysin oikea tulos. Käytetään kuitenkin näitä
opetusjoukon näytteitä merkitsemään, joka klusteriin, mitä sanaa se
edustaa. Siis se klusteri, jossa on enemmän merkitystä A (suhteessa
kummankin merkityksen opetusjoukon kokoon) väittää,
että kaikki sen lähelle tippuvat näytteet nyt kuuluvat varmasti
merkitykseen A. Kokeillaan seuraavaksi testijoukkoa näitä
merkityksiä vasten ja katsotaan, kuinka paljon merkityksistä menee
oikein.
Menetelmää käyttäen saadaan taulukossa 1 annetut
tulokset. Tässä käytettiin 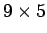 kokoista karttaa. Jos oikeita
vastauksia ei ole saatavilla, on silmämääräisesti helpompi arvioida
tulokset vähemmästä määrästä ryhmiä. Esim. sanoilla ``sade'' ja
``komissio'',
kokoista karttaa. Jos oikeita
vastauksia ei ole saatavilla, on silmämääräisesti helpompi arvioida
tulokset vähemmästä määrästä ryhmiä. Esim. sanoilla ``sade'' ja
``komissio'',
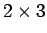 kartan tulokset olivat 59 % ja 98%.
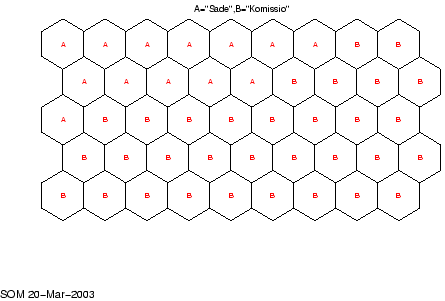
Kuvassa 2 on annettu sanojen ``sana'' ja ``komissio''
ryhmittyminen
kartalle.
kartan tulokset olivat 59 % ja 98%.
Kuvassa 2 on annettu sanojen ``sana'' ja ``komissio''
ryhmittyminen
kartalle.
Taulukko:
Tulokset, kartta
| |
|
opetus |
testi |
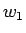 |
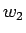 |
oikein % |
oikein % |
oikein % |
oikein % |
| Lappi |
Pariisi |
63 |
55 |
61 |
53 |
| sade |
komissio |
66 |
93 |
66 |
92 |
| Venäjä |
tammikuu |
80 |
60 |
78 |
60 |
| Halonen |
TPS |
62 |
74 |
63 |
70 |
| leijona |
ydinvoima |
70 |
55 |
75 |
48 |
Kuva:
kartta
 |
vsiivola@cis.hut.fi