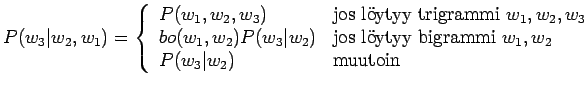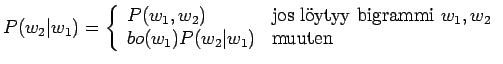a) Tehtävänäsi on arvioida sanoja ``tuntumaan jo'' seuraavan sanan todennäköisyydet. Mahdollisia jatkosanoja ovat
- ja
- hyvältä
- kumisaapas
- keväältä
- ilman
- päihtyneeltä
- turhalta
- koirineen
- öljyiseltä
- Turku
Vertaa antamiasi estimaatteja kielioppiaineistosta laskettuihin (tasoittamattomiin) estimaatteihin. Kumpi antoi paremman todennäköisyyden oikealle sanalle ?
b) Tiedät koko lauseen alun, joka on ``Leuto sää ja soidinmenonsa aloittaneet tiaiset ovat saaneet helmikuun tuntumaan jo X''. Arvioi nyt tämän kontekstin perusteella uudestaan annettujen sanojen todennäköisyydet.
c) Mitä erilaisia tietoja kielioppimalli tarvitsisi, jotta se pystyisi vastaamaan ihmisen suorituskykyyn b)-kohdassa ?
Alkuperäisessä lauseessa ollut sana löytyy paperin kääntöpuolelta.
- a)
- Laske 1. tehtävän sanoista uni-, bi- ja trigrammimallit.
- b)
- Tasoita estimaatit Laplacen menetelmällä. Oleta sanaston kooksi 20000 sanaa.
- c)
- Tasoita sanasto Lidstonen menetelmällä.
|
Taulukossa annettu perääntyvän (back-off) kielimallin todennäköisyydet voidaan laskea seuraavasti: