Since the distribution of the weight vectors of the SOM approximates that of the training data, the SOM can be utilized in estimating the probability density function (PDF) of a data set. The estimation can be done using e.g. the reduced kernel density estimation (RKDE) [10]:
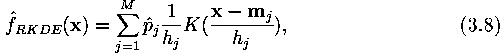
where M is the number of neurons in the map, K is a
kernel function and the weights ![]() and the smoothing
parameters
and the smoothing
parameters ![]() are estimated from the data. The batch version
of the algorithm proceeds as follows:
are estimated from the data. The batch version
of the algorithm proceeds as follows: