
T-61.6030 Special Course in Computer and Information Science III P: Multimedia Retrieval
New: Added ground truth files for test set 2. Available here (4.4 MB).
|
The project work involves semantic image classification based on a set of precomputed low-level features. The selection of the used classification algorithm is free, but the provided examples apply support vector machines using the LIBSVM implementation. The deadline for the project work is May 19th, 2008. |
|
We use the image data from The PASCAL Visual Object Classes Challenge 2005, datasets 1 and 2. The data sets contain a total of 2329 images of motorbikes, bicycles, people, and cars in arbitrary pose. The set is divided into a training set of 684 images, and two test sets containing 689 and 956 images, respectively. You may download the original images from the challenge website for reference, although it is possible to do the project work entirely based on the provided low-level features. The set of pre-computed low-level features are:
The feature data can be found here in LIBSVM format (6.8 MB). The classwise ground truth for test set 2 is also available (4.4 MB). See the LIBSVM README file for a description of the format.
The file names of the images in correct order are given in the files For more details about the features, see the MPEG-7 overview and this ICCV 2003 paper by Gy. Dorkó and C. Schmid. |
|
The task is to train classifiers for the four concepts (motorbikes, bicycles, people,
and cars) using the training set and then test the classifiers using the test sets. The examples
shown in this section use the command-line version of
LIBSVM, but you are free to use any other
implementation or algorithm. In particular, there is a Matlab interface for LIBSVM available if you
prefer to use Matlab. Also, you can use the included An example SVM classifier In the following, we assume that you have downloaded (and compiled) LIBSVM, and have all the
low-level feature files in a subdirectory First, let us scale the training and test sets into the range [-1,1]: LIBSVM provides a tool for SVM parameter estimation using grid search and cross-validation: Once we have the parameter values, we are ready to train the SVM classifier: The classifier is tested using the images in the test set 1: Fundamentals Train models for all four concepts using the given features. Report the results of test set 1 with the concept-wise and overall
classification accuracy and average precision (see Chapter 13 in the course book). You may also use some other suitable
information retrieval measures such as recall-precision curves or receiver operating characteristic (ROC) curves.
For these measures, you need to look at the individual probability estimates in the For test set 2, return an ordered list of the images for each concept as separate text files, one image per line. The lists should contain the images that your method finds most probable for being relevant to the given concept, in decreasing order. The lists may or may not contain all 956 images, but the performance may suffer if you return only partial lists. We will then calculate the mean average precision for all submitted experiments and publish the results on the course web page. Submit the lists for only your best method or methods to Mats Sjöberg (mats.sjoberg (at) tkk.fi) before April, 21st, 2008. Improvements There are a number of ways you can extend your experiments:
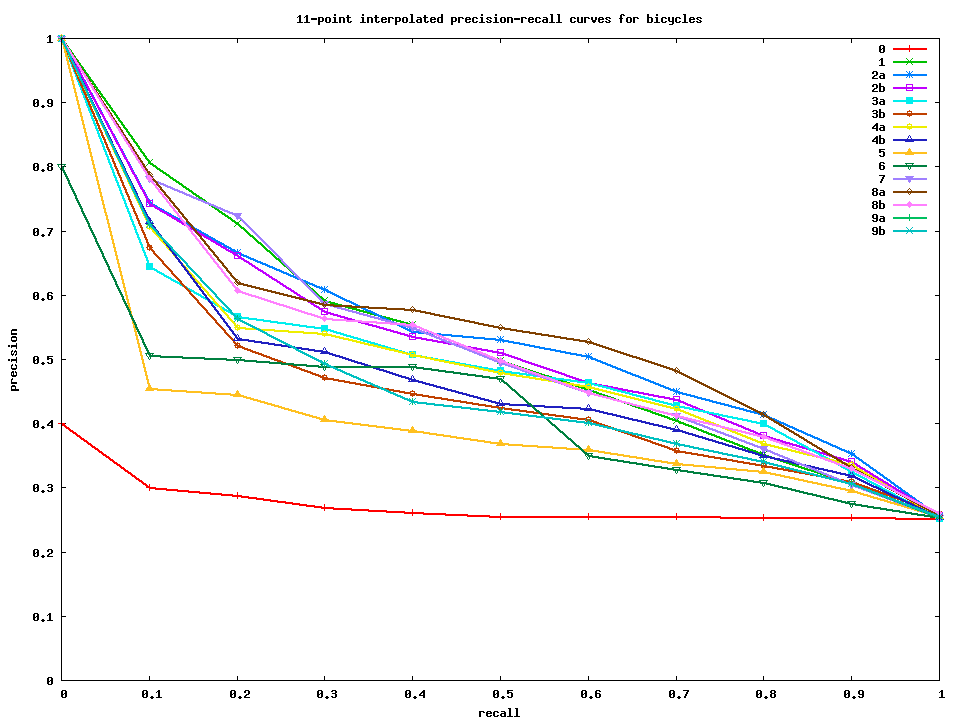
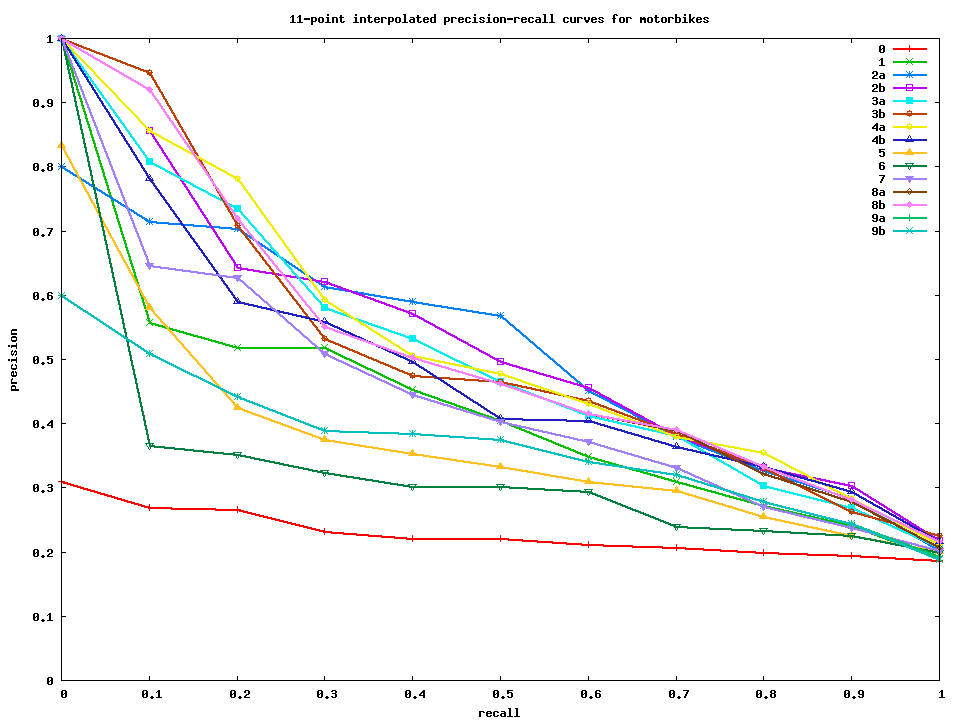
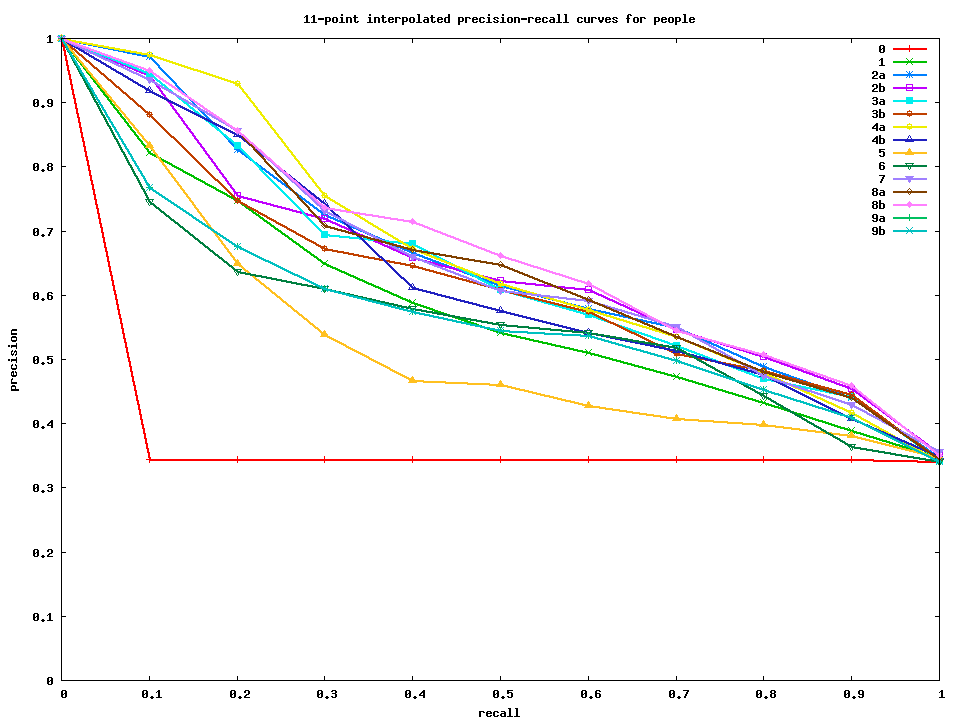
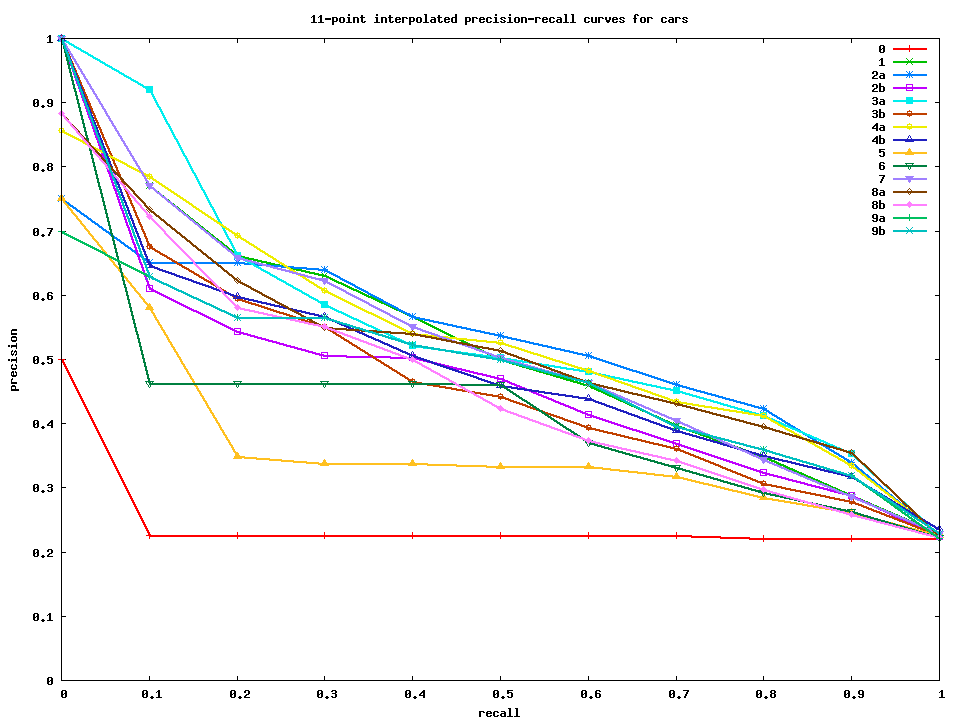
Select and include at least two items from the list to your project. Test set 2 results The average precision results for submitted test set 2 runs are as follows:
Interpolated precision-recall curves for bicycles, motorbikes, people, and cars. Gnuplot and data files for making these curves are also available. |
|
The results of the project work should be reported in a scientific conference style paper, which should be understandable as such, i.e. without these instructions, and complete with a title, abstract, introduction, methods, results and discussion sections, and references. Send the final report in PDF format to Mats Sjöberg (mats.sjoberg (at) tkk.fi). The deadline for the project work is May 19th, 2008. The report can be written in English, Finnish, or Swedish. |
You are at: [an error occurred while processing this directive]Project work
Page maintained by markus.koskela (at) tkk.fi, last updated Monday, 12-May-2008 15:37:02 EEST
{kind=link}
{kind=link}
{kind=link}
{kind=link}