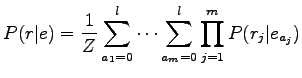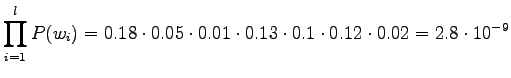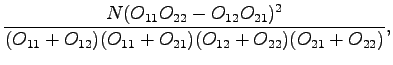T-61.5020 Luonnollisten kielten tilastollinen käsittely
Vastaukset 9, to 28.3.2007, 12:15-14:00 -- Tilastollinen konekääntäminen
Versio 1.0
- 1.
- Etsitään todennäköisin käännös
 ruotsinkieliselle lauseelle
ruotsinkieliselle lauseelle 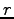 :
:
Käytetään kirjassa esitettyä mallia todennäköisyydelle 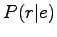 :
:
missä 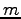 on alkuperäisen ruotsinkielisen lauseen pituus ja
on alkuperäisen ruotsinkielisen lauseen pituus ja 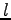 on
käännetyn englanninkielisen lauseen pituus. Lasketaan
kummallekin vaihtoehdolle:
on
käännetyn englanninkielisen lauseen pituus. Lasketaan
kummallekin vaihtoehdolle:
Tässä siis kokeillaan kaikkia käännössääntöjä jokaiselle
ruotsinkielisen lauseen sanalle (huomioimatta sanajärjestystä).
Koska säännöstö on hyvin harva, päästään näin yksinkertaiseen
laskutoimitukseen.
Prioritodennäköisyys 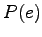 saadaan kielimallista. Lasketaan se
kummallekin lauseelle:
saadaan kielimallista. Lasketaan se
kummallekin lauseelle:
Kertomalla priori ja käännöstodennäköisyys huomataan, että
jälkimmäinen käännös on todennäköisempi:
Huomattavaa on, että käännösmalli ei ota mitään kantaa
sanajärjestykseen. Koska myöskään kielimalli (unigrammimalli) ei
tätä tee, mallin mielestä sanajärjestyksellä ei ole mitään
merkitystä. Jos mallilta kysytään todennäköisintä lausetta (ei
testata eri vaihtoehtoja) huomataan, että todennäköisimpään
lauseeseen ei voi tulla artikkeleja eikä sanaa ``into''. Tämä johtuu
siitä, että niiden lisääminen ei muuta käännöstodennäköisyyttä,
mutta tiputtaa aina kielimallitodennäköisyyttä. Kielimalli siis
suosii muutenkin lyhyempiä lauseita. Kasvattamalla kielimallin
konteksti trigrammiksi, saisi ehkä artikkelit ja sanajärjestyksen
paremmin kohdalleen.
Yleisesti tällä menetelmällä tarvitaan heuristiikkaa valitsemaan
käännökset, joita tutkitaan. Kaikkien vaihtoehtojen läpikäynti on
käytännössä mahdotonta.
- 2.
- Käytetään esimerkkisanaa
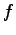 = ``tosiasia''.
Se on esiintynyt korpuksessa 989 kertaa. Normalisointia varten
aineistosta pitää laskea erikseen kaikkien englannin sanojen
esiintymismäärät.
= ``tosiasia''.
Se on esiintynyt korpuksessa 989 kertaa. Normalisointia varten
aineistosta pitää laskea erikseen kaikkien englannin sanojen
esiintymismäärät.
Allaolevassa taulukossa on 20 suurinta arvoa saanutta
englannin sanaa yhteisesiintymien frekvenssin sekä englannin sanan
esiintymismäärällä normalisoidun frekvenssin mukaisesti.
Nähdään että kumpikaan menetelmä ei annan toivottuja tuloksia.
Ensimmäisessä ovat ongelmana hyvin yleiset sanat, joita esiintyy
lähes jokaisessa lauseessa ja siten myös yhtäaikaa :n kanssa.
Jälkimmäisessä taas ongelmaksi muodostuvat hyvin harvinaiset sanat:
Jos kerran esiintynyt sanaa sattuu esiintymään yhtä aikaa :n kanssa,
se saa suurimman mahdollisen arvon.
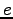 |
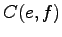 |
| the |
2563 |
| of |
1128 |
| that |
1086 |
| is |
1040 |
| and |
829 |
| to |
823 |
| in |
726 |
| a |
716 |
| fact |
654 |
| it |
385 |
| this |
376 |
| we |
316 |
| are |
295 |
| not |
280 |
| for |
274 |
| have |
253 |
| be |
234 |
| which |
230 |
| on |
224 |
| has |
212 |
|
|
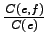 |
| winkler |
1.0000 |
| visarequired |
1.0000 |
| visaexempt |
1.0000 |
| veiling |
1.0000 |
| valuejudgment |
1.0000 |
| undisputable |
1.0000 |
| stayers |
1.0000 |
| semipermeable |
1.0000 |
| rulingout |
1.0000 |
| roentgen |
1.0000 |
| residuarity |
1.0000 |
| regionallevel |
1.0000 |
| redhaired |
1.0000 |
| poorlyfounded |
1.0000 |
| philippic |
1.0000 |
| pemelin |
1.0000 |
| paiania |
1.0000 |
| overcultivation |
1.0000 |
| outturns |
1.0000 |
| onesixth |
1.0000 |
|
Edellisissä menetelmissä oli ongelmana että ne
eivät ottaneet huomioon käännöksen molempia suuntia:
Jotta olisi todennäköinen käännös :lle, :n pitäisi
esiintyä niissä lauseissa joissa esiintyi, sekä :n
pitäisi esiintyä niissä lauseissa joissa esiintyi.
Tällöin todennäköisyyksien
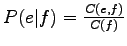 sekä
sekä
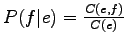 pitäisi kummankin
olla suuria. Kokeillaan seuraavana painotuksena näiden
todennäköisyyksien tuloa.
pitäisi kummankin
olla suuria. Kokeillaan seuraavana painotuksena näiden
todennäköisyyksien tuloa.
Tulokset ovat seuraavan sivun vasemmanpuoleisessa taulukossa.
Tällä kertaa löydettiin oikea käännös, ja myös toinen merkitykseltään
läheinen sana ``reality'' on suhteellisen korkealla.
Kokeillaan vielä kollokaatiolaskarista tuttua 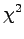 -testiä:
-testiä:
missä
ja 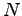 aineiston kaikkien lauseiden määrä. Yli 3.843 arvon saaville
sanoille tulokset tarkoittavat, että todennäköisyys sille että
yhteisesiintymät olivat sattuman aikaansaamia, on alle 5%.
aineiston kaikkien lauseiden määrä. Yli 3.843 arvon saaville
sanoille tulokset tarkoittavat, että todennäköisyys sille että
yhteisesiintymät olivat sattuman aikaansaamia, on alle 5%.
Suurimmat arvot saaneet sanat ovat oikeanpuoleisessa taulukossa.
Testi näyttää toimivan erittäin hyvin: Ainoastaan ``fact''
ylitti luotettavuusrajan. Toisaalta jos haluisimme vaihtoehtoisia
käännöksiä, kuten ``reality'', joku todennäköisyysarvon antava
menetelmä olisi käyttökelpoisempi. Käytännössä käännöstodennäköisyydet
etsitään iteratiivisesti EM-algoritmilla, jolloin rajoitetaan sitä
että yksi englannin sana olisi monen suomenkielisen sanan käännös,
mutta esitetyn kaltainen menetelmä voisi toimia todennäköisyyksien
alustuksena.
|
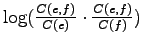 |
| fact |
-3.9758 |
| the |
-5.6159 |
| that |
-5.8849 |
| is |
-5.9086 |
| reality |
-6.0057 |
| winkler |
-6.2035 |
| of |
-6.4963 |
| hedgehog |
-6.6090 |
| a |
-6.6577 |
| and |
-6.8386 |
| visarequired |
-6.8967 |
| visaexempt |
-6.8967 |
| veiling |
-6.8967 |
| valuejudgment |
-6.8967 |
| undisputable |
-6.8967 |
| stayers |
-6.8967 |
| semipermeable |
-6.8967 |
| rulingout |
-6.8967 |
| roentgen |
-6.8967 |
| residuarity |
-6.8967 |
|
|
|
| fact |
18.2155 |
| the |
3.5937 |
| that |
3.0070 |
| is |
2.8096 |
| of |
2.3485 |
| reality |
2.3166 |
| winkler |
2.0000 |
| hedgehog |
1.3323 |
| visarequired |
1.0000 |
| visaexempt |
1.0000 |
| veiling |
1.0000 |
| valuejudgment |
1.0000 |
| undisputable |
1.0000 |
| stayers |
1.0000 |
| semipermeable |
1.0000 |
| rulingout |
1.0000 |
| roentgen |
1.0000 |
| residuarity |
1.0000 |
| regionallevel |
1.0000 |
| redhaired |
1.0000 |
|
svirpioj@cis.hut.fi