|
Tarkemmalla tukimisilla huomataan, että taulukossa ihmisen antamat trigrammiestimaatit ovat jonkin verran pielessä ja tilastolliset pehmentämättömät trigrammiestimaatit aivan pielessä.
Tilastollisten estimaattien laskuun käytettiin n. 30 miljoonan sanan aineistoa. Tässä aineistossa ei yksikään annetuista taivutetuista trigrammeista esiintynyt kertaakaan. Trigrammit perusmuotoistamalla löydettiin 11 lausetta, joissa esiintyi ``tuntua jo hyvä''. Estimaatti kaipaa siis selvästi tasoittamista, eikä senkään jälkeen ole kovin luotettava.
Myös esimerkki-ihmisen antamaa estimaattia voi epäillä, aivan mahdollisille lauseille on annettu nollatodennäköisyys, esim. ``Kyllä alkaa tuntumaan jo kumisaapas jalassa'', lause joka voidaan tokaista vaikka pitkän vaelluksen päätteeksi. Toisaalta annetulla 2 desimaalin tarkkuudella estimaatit lienevät hyviä.
Kun testihenkilölle annettiin koko lause nähtäväksi, saatiin jo varsin laadukkaat estimaatit. Jotta tilastollisesti pystyttäisiin pääsemään samaan tulokseen, tarvitsisi mallin ymmärtää suomen kielen syntaksia (miten sanoja voidaan taivuttaa ja laittaa peräkkäin) sekä myös sanojen semanttista merkitystä (``helmikuu'' on lopputalvea, melkein kevättä).
- a)
- Suurimman uskottavuuden estimaatit voidaan laskea kaavasta
missä funktio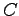 kertoo opetusjoukossa nähtyjen näytteiden määrän.
kertoo opetusjoukossa nähtyjen näytteiden määrän.
Unigrammiestimaatissa unohdetaan riippuvuus kaikista edellisistä sanoista, bigrammiestimaatti riippuu vain edellisestä sanasta ja trigrammiestimaatissa käytetään historiana kahta edellistä sanaa.
Unigrammiestimaatit voidaan siis laskea
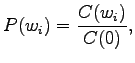
missä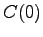 on opetusjoukon näytteiden lukumäärä. Estimaatit ovat
siis samat kummallekin tehtävänannon historialle.
on opetusjoukon näytteiden lukumäärä. Estimaatit ovat
siis samat kummallekin tehtävänannon historialle.
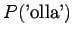
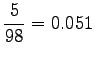
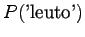
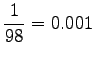
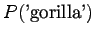
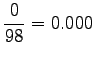
Bigrammiestimaatit saadaan ottamalla yksi sana historiasta käyttöön:
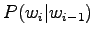
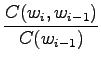
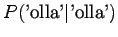
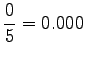
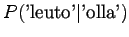
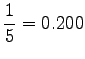

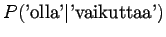
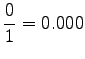
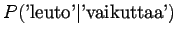
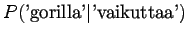
Huomataan, että tämän mallin mielestä mikään sanayhdistelmä, jota se ei ole nähnyt, ei ole mahdollinen. - b)
- Laplacen estimaatissa aikaisemmin havaitsemattomille
sanoille annetaan hieman todennäköisyyttä. Estimaatti vastaa
prioria, että kaikki sanat ovat yhtä todennäköisiä. Käytännössä se
lasketaan niin, että kuvitellaan että kaikkia sanoja on jo nähty
kerran:
missä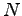 on mallin sanaston koko.
on mallin sanaston koko.
Lasketaan siis estimaatit:
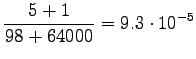
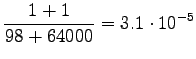
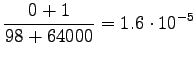
Bigrammeille:
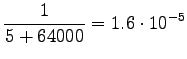
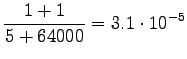
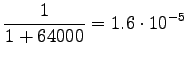
Huomataan, että tässä priorioletus, että kaikki sanat ovat yhtä todennäköisiä ohjaa estimaatteja vahvasti, kaikki sanat ovat toisaan mallien mielestä lähes yhtä todennäköisiä. - c)
- Lidstonen estimaatissa voidaan säätää sitä, kuinka paljon uskotaan
siihen, että sanat ovat yhtä todennäköisiä. Siinä kuvitellaan,
että sanat on jo nähty
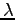 kertaa ennen opetusaineistoa:
kertaa ennen opetusaineistoa:
Valitaan tässä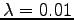 . Lasketaan estimaatit:
. Lasketaan estimaatit:
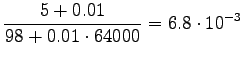
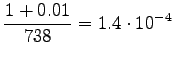
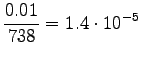
Bigrammeille:
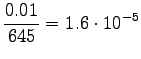
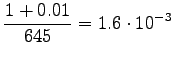
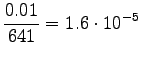
Tässä tapauksessa opetusdata ohjaa selkeämmin estimaatteja. Sopiva voidaan valita laittamalla
opetusjoukosta pieni osa sivuun ja testaamalla tällä sivuun
laitetulla tekstillä, mikä toimii parhaiten.
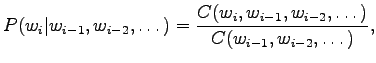
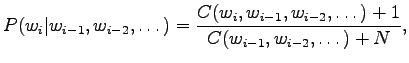
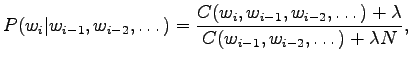
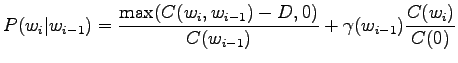
Tässä
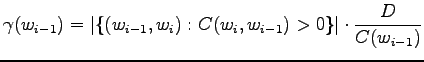 |
Aloitetaan laskemalla historioille ``olla'' ja ``vaikuttaa'' nämä
interpolointikertoimet. Historialla ``olla'' on esiintynyt viisi
erilaista seuraajaa ja se on yhteensä esiintynyt viisi kertaa.
Historialla ``vaikuttaa'' on yksi esiintynyt seuraaja, ja esiintymiä
myös yksi. Siispä:
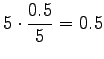 |
|||
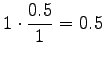 |
Nyt voidaan laskea interpoloidut bigrammitodennäköisyydet:
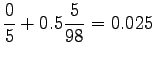 |
|||
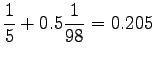 |
|||
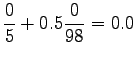 |
|||
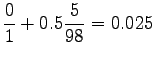 |
|||
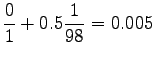 |
|||
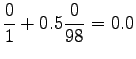 |
Huomataan että menelmä ei tälläisenään anna yhtään todennäköisyyttä opetusaineiston ulkopuoliselle sanastolle (gorilla). Tämä voitaisiin korjata käyttämällä unigrammitodennäköisyyksille vielä jotain tasoitusmenetelmää. Mahdollista olisi myös jatkaa interpolointia niin sanoittuihin nollagrammeihin, mikä tarkoittaa tasajakauman kanssa interpolointia.
Interpolointi tai peräytyminen matalamman asteen n-grammeihin ei
kuitenkaan aina ole täysin luotettavaa. Esimerkkinä voidaan tarkastella
bigrammia ``San Francisco''. Koska paikannimi on hyvin tunnettu, estimaatti
![]() on todennäköisesti
luotettava. Eli jos edellinen sana on ``San'', ei tule ongelmia.
Mutta entä jos edellinen sana ei ollut ``San''? Tällöin Fanciscon
todennäköisyyden pitäisi olla selvästi pienempi kuin silloin, kun
tarkastellaan unigrammijakaumaa ilman tietoa edellisestä sanasta.
Tähän ideaan pohjautuu Kneser-Ney -tasoitus, jossa alemman asteen
n-grammien todennäköisyydet estimoidaan arvioimalla kuinka
todennäköistä sanan on esiintyä uudessa kontekstissa.
Tällä hetkellä parhaaksi todettu tasoitusmenetelmä on juuri modifioitu
Kneser-Ney -interpolointi, joka käyttää näiden tyyppiestimaattien
lisäksi absoluuttista vähennystä kolmella erikseen optimoitavalla
vakiolla.
on todennäköisesti
luotettava. Eli jos edellinen sana on ``San'', ei tule ongelmia.
Mutta entä jos edellinen sana ei ollut ``San''? Tällöin Fanciscon
todennäköisyyden pitäisi olla selvästi pienempi kuin silloin, kun
tarkastellaan unigrammijakaumaa ilman tietoa edellisestä sanasta.
Tähän ideaan pohjautuu Kneser-Ney -tasoitus, jossa alemman asteen
n-grammien todennäköisyydet estimoidaan arvioimalla kuinka
todennäköistä sanan on esiintyä uudessa kontekstissa.
Tällä hetkellä parhaaksi todettu tasoitusmenetelmä on juuri modifioitu
Kneser-Ney -interpolointi, joka käyttää näiden tyyppiestimaattien
lisäksi absoluuttista vähennystä kolmella erikseen optimoitavalla
vakiolla.
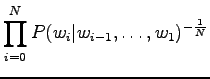 |
|||
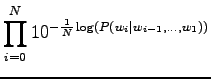 |
|||
Lasketaan summa erikseen:
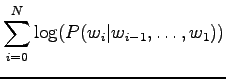 |
|||
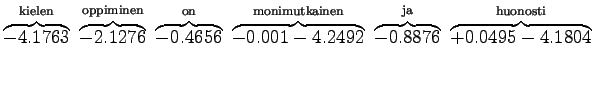 |
|||
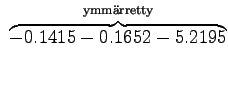 |
|||
Niille sanoille, joille ei löytynyt trigrammimallia, jouduttiin käyttämään sekä perääntymiskerrointa että todennäköisyyttä. Jos myöskään bigrammimallia ei löytynyt, jouduttiin vielä kerran perääntymään.
Sijoitetaan vielä luvut hämmentyneisyyden lausekkeeseen
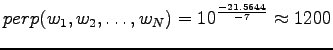 |
Tulosta voi ajatella vaikka niin, että kielimalli vastaa sellaista kielimallia, joka joutuu valitsemaan 1200 yhtä todennäköisen sanan väliltä (ei ihan eksaktisti paikkansapitävä väite).
Sana ``tapahtumaketju'' ei ollut 64000 yleisimmän sanan joukossa ja ei
sisältynyt siis kielimalliin. Kielimallin ohi meni siis
![]() sanoista.
sanoista.