Seuraavassa taulukossa on annettu mittojen määritelmät ja sijoitettu
luvut.
|
F-mitta määritellään tarkuuden ja palautuksen avulla:
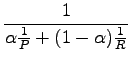 |
missä P on tarkkuus ja R on palautus.
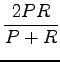 |
Ensimmäiselle koneelle saadaan näinollen
Interpoloimatonta keskitarkkuutta laskiessa katsotaan tarkkuutta
aina kun löydetään relevantti dokumentti ja keskiarvoistetaan näiden
tarkkuuksien yli. Relevantit dokumentit, joita ei palautettu, lasketaan
mukaan tarkkuudella 0.
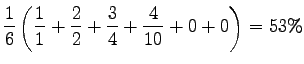 |
|||
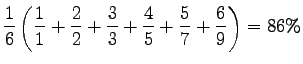 |
Residuaalisen käänteisen dokumenttifrekvenssin (RIDF) kohdalla kirjan
ensimmäisessä painoksessa on runsaasti virheitä. RIDF:n kantava
idea perustuu seuraavanlaiselle päättelylle: Voimme mallintaa
sanan esiintymistä Poisson-jakaumalla ![]() . Tämä toimii hyvin
sanoille, jotka ovat suhteellisen tasaisesti jakautuneet
korpuksessa. Sisällöllisesti merkittävät sanat esiintyvät yleensä
ryhmissä asiaa käsittelevän dokumentin sisällä, ja Poisson-jakauma
antaa siis tällöin väärän ennusteen sanojen yleisyydestä. RIDF:ssä
mitataan käänteisen dokumenttifrekvenssin ja Poisson-jakauman
välistä eroa. Mitä suurempi ero, sitä enemmän sana kuvaa
dokumentin sisältöä.
. Tämä toimii hyvin
sanoille, jotka ovat suhteellisen tasaisesti jakautuneet
korpuksessa. Sisällöllisesti merkittävät sanat esiintyvät yleensä
ryhmissä asiaa käsittelevän dokumentin sisällä, ja Poisson-jakauma
antaa siis tällöin väärän ennusteen sanojen yleisyydestä. RIDF:ssä
mitataan käänteisen dokumenttifrekvenssin ja Poisson-jakauman
välistä eroa. Mitä suurempi ero, sitä enemmän sana kuvaa
dokumentin sisältöä.
Tässä siis Poisson-jakauman käyttölogiikka on seuraava:
Approksimodaan, että dokumentissä esiintyy sana ![]() keskimäärin
keskimäärin
![]() kertaa. Todennäköisyys sille, että
jossain tietyssä dokumentissä sana
kertaa. Todennäköisyys sille, että
jossain tietyssä dokumentissä sana ![]() esiintyy
esiintyy ![]() kertaa
saadaan Poisson-jakaumasta
kertaa
saadaan Poisson-jakaumasta
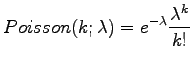 |
RIDF määritellään siis
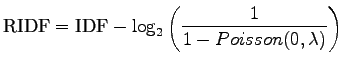 |
Tässä siis Poisson-jakaumasta otetaan todennäköisyys, että dokumentissä esiintyy haluttu sana vähintään kerran (
Sievennellään RIDF:n lauseketta:
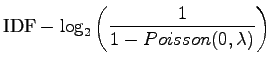 |
|||
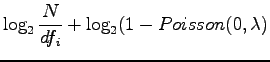 |
|||
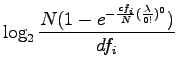 |
|||
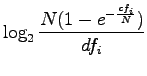 |
Sijoitellaan kaavaan luvut:
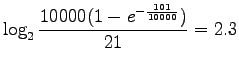 |
|||
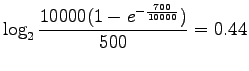 |
Huomataan, että RIDF painotti sanaa ![]() 2.5 kertaa enemmän kuin
IDF. Molempien menetelmien mielestä
2.5 kertaa enemmän kuin
IDF. Molempien menetelmien mielestä ![]() on relevantimpi
hakutermi kuin
on relevantimpi
hakutermi kuin ![]() .
.
SVD-hajotelmassa (Singular Value Decomposition) puretaan
![]() (
(![]() ) matriisi
) matriisi ![]() palasiksi:
palasiksi:
Tässä
Lasketut matriisit on esitetty taulukoissa 4,
5 ja 6. (Matlab palauttaa oletuksena hieman
erilaiset matriisit kuin mitä yllä mainittiin: Nyt ![]() on
on
![]() ,
,
![]()
![]() ja
ja ![]()
![]() . Käytännön merkitystä asialla
ei ole; singulaariarvot, niiden määrä ja tulos dimension pudotuksen
jälkeen ovat samoja.)
. Käytännön merkitystä asialla
ei ole; singulaariarvot, niiden määrä ja tulos dimension pudotuksen
jälkeen ovat samoja.)
|
|
|
|
|
Tiputetaan sisäinen dimensio kahteen jättämällä ![]() ja
ja ![]() -matriiseista muut dimensiot pois ja ottamalla
-matriiseista muut dimensiot pois ja ottamalla ![]() -matriisista vain
kaksi suurinta ominaisarvoa. Nyt dokumenttien samankaltaisuutta voi
verrata matriisilla
-matriisista vain
kaksi suurinta ominaisarvoa. Nyt dokumenttien samankaltaisuutta voi
verrata matriisilla ![]() . Jos matriisin sarakeet skaalataan yhden
pituisiksi, on helppo laskea korrelaatioita rivien välillä. Tällainen
skaalattu matriisi on esitetty taulukossa 7 ja siitä
lasketut korrelaatiot taulukossa 8. Sanojen
samankaltaisuutta voitaisiin verrata matriisista
. Jos matriisin sarakeet skaalataan yhden
pituisiksi, on helppo laskea korrelaatioita rivien välillä. Tällainen
skaalattu matriisi on esitetty taulukossa 7 ja siitä
lasketut korrelaatiot taulukossa 8. Sanojen
samankaltaisuutta voitaisiin verrata matriisista ![]() .
Korrelaatiomatriisista huomataan, että formula-artikkelit ja
tähtitiedeartikkelit korreloivat sisäisesti paljon enemmän kuin
ristiin. Alunperin täysin korreloimattomata dokumentit
.
Korrelaatiomatriisista huomataan, että formula-artikkelit ja
tähtitiedeartikkelit korreloivat sisäisesti paljon enemmän kuin
ristiin. Alunperin täysin korreloimattomata dokumentit ![]() ja
ja ![]() korreloivat nyt selvästi. Olemme projisoineet datan
2-ulotteiseen avaruuteen ja samantyyppiset artikkelit ovat päätyneet
lähekkäin tähän alempiulotteiseen avaruuteen.
korreloivat nyt selvästi. Olemme projisoineet datan
2-ulotteiseen avaruuteen ja samantyyppiset artikkelit ovat päätyneet
lähekkäin tähän alempiulotteiseen avaruuteen.
Lopuksi vielä pieni varoitus: kirjan kappaleessa 15 on runsaasti pikkuvirheitä, kannattaa tarkastaa kirjan errata (http://www-nlp.stanford.edu/fsnlp/errata.html).