- a)
- Sijoitetaan entropian kaavaan
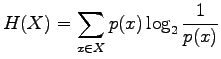
tehtävässä annetut arvot:
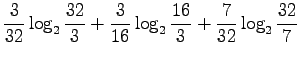
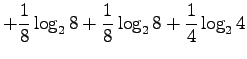
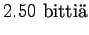
- b)
- Tehtävän ratkaisuun tarvitaan todennäköisyyttä
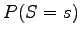 (eli satunnainen
substantiivi on
(eli satunnainen
substantiivi on 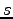 ). Tämä todennäköisyys saadaan tehtävänannon
taulukon oikeasta marginaalista. Lisäksi tarvitaan todennäköisyyttä
). Tämä todennäköisyys saadaan tehtävänannon
taulukon oikeasta marginaalista. Lisäksi tarvitaan todennäköisyyttä
Lähteen entropia, kun tiedetään, että edellinen symboli kuului joukkoon
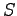 on
on
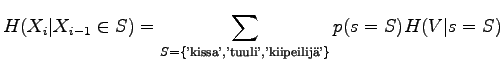
Tämän laskemiseksi meidän pitää osata laskea ehdollinen entropia
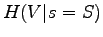 . Lasketaan tämä sanalle 'kissa':
. Lasketaan tämä sanalle 'kissa':
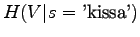

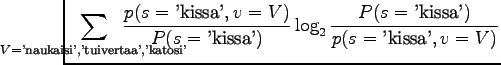
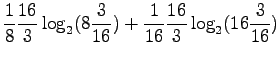
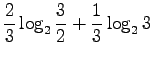
Kun sijoitamme jokaista joukon sanaa vastaavat todennäköisyydet, saamme
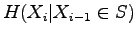
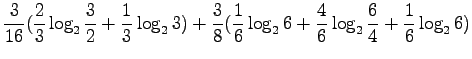
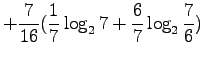
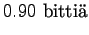
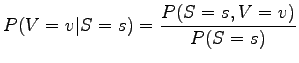
Mikä on sitten todennäköisyys, että satunnainen sana on 'kissa'?
Koska molemmat luokat ![]() ja
ja ![]() ovat yhtä todennäköiset, tulos on
ovat yhtä todennäköiset, tulos on
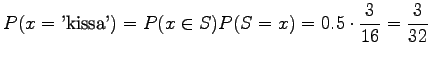 |
Huomaamme, että a)-kohta on itseasiassa b)-kohdan marginaalijakauma.
Tästä voimme päätellä, että kun tunnemme lähteen toiminnan paremmin, sen tuottamat sanat ovat vähemmän yllättäviä ja voimme koodata ne vähemmällä määrällä bittejä (0.9 bittiä < 2.5 bittiä).
- c)
- Kielen lauseissa ensimmäinen sana on aina substantiivi ja toinen verbi.
Substantiivi ei riipu edellisistä sanoista, mutta verbi riippuu edellisestä
substantiivista.
Merkitään kielen lausetodennäköisyyksiä
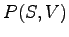 ja mallin antamia
todennäköisyyksiä
ja mallin antamia
todennäköisyyksiä 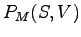 . Haluamme laskea odotusarvon kielen lauseen
koodauspituudelle mallin antamilla todennäköisyyksillä:
. Haluamme laskea odotusarvon kielen lauseen
koodauspituudelle mallin antamilla todennäköisyyksillä:
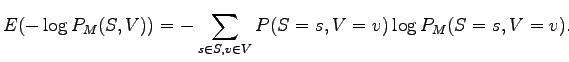
Tätä mittaa kutsutaan risti-entropiaksi (cross-entropy).Mallin antamat verbien ja substantiivien todennäköisyydet ovat toisistaan riippumattomia, joten
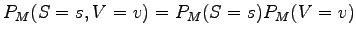 . Sijoitetaan se
lausekkeeseen, ja kirjoitetaan summaus auki ensin substantiivien ja sitten
verbien osalta:
. Sijoitetaan se
lausekkeeseen, ja kirjoitetaan summaus auki ensin substantiivien ja sitten
verbien osalta:
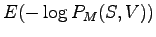
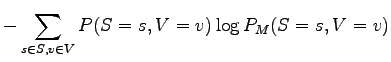
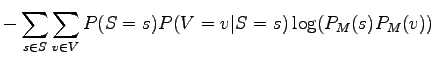
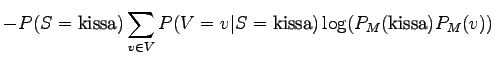
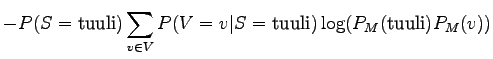
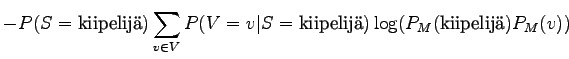
![$\displaystyle - \frac{3}{16} \cdot
\big[\frac{1}{8}\frac{16}{3} \log(\frac{3}{32} \frac{1}{8}) +
\frac{1}{16}\frac{16}{3} \log(\frac{3}{32} \frac{1}{4}) \big]$](img34.png)
![$\displaystyle - \frac{3}{8} \cdot
\big[\frac{1}{16}\frac{8}{3} \log(\frac{3}{16...
...16} \frac{1}{8}) +
\frac{1}{16}\frac{8}{3} \log(\frac{3}{16} \frac{1}{4}) \big]$](img35.png)
![$\displaystyle - \frac{7}{16} \cdot
\big[\frac{1}{16}\frac{16}{7} \log(\frac{7}{32} \frac{1}{8}) +
\frac{3}{8}\frac{16}{7} \log(\frac{7}{32} \frac{1}{4}) \big]$](img36.png)
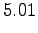
Lauseden keskimääräinen koodauspituus (ts. risti-entropia lausetta kohti) on siis 5.01 bittiä.Jokaisessa lauseessa on kaksi sanaa, joten keskimääräinen yhden sanan koodauspituus on 2.50 bittiä. Tulos on sama kuin a)-kohdassa, eikä se ole sattumaa: Kummassakin tapauksessa jakauma, jonka yli odotusarvo mallin antamille koodauspituuksille lasketaan, on sama.
- a)
- Kunkin alkeistapauksen todennäköisyys on
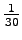 . Alkeistapauksia on 30. Sijoitetaan entropian kaavaan:
. Alkeistapauksia on 30. Sijoitetaan entropian kaavaan:
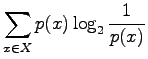
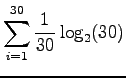
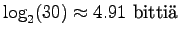
- b)
- Sanan, jossa on vain yksi merkki, sanotaan vaikka joukon
ensimmäinen merkki, todennäköisyys on
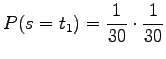
sillä ensimmäisen merkin pitää olla joukon ensimmäinen ja sitten pitää tulla sanaväli. Tällaisia sanoja on 29 kappaletta.Vastaavasti, tietyn kahden merkin pituisen sanan todennäköisyys on
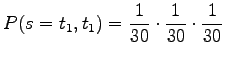
Tällaisia sanoja on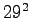 kappaletta. Homma jatkuu samalla tavalla
useammille sanoille.
kappaletta. Homma jatkuu samalla tavalla
useammille sanoille.
Lasketaan tällaisen lähteen entropia:
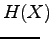

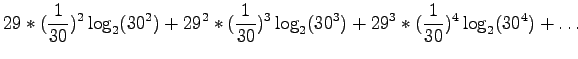
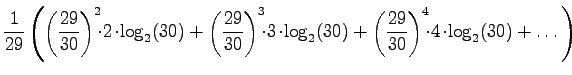
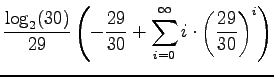
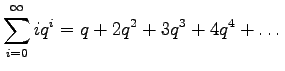
Kerrotaan yhtälö
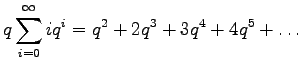
Vähennetään yhtälö 2 puolittain yhtälöstä 1
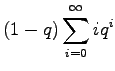
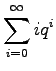
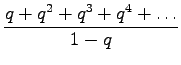
Kerrotaan yhtälö 4 vielä kerran
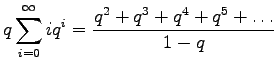
Nyt vähennetään yhtälöt 4 ja 5 toisistaan ja saadaan ratkaisu:
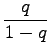
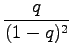
Tässä ratkaisussa pitää vielä huomioda, että jotta yhtälö 2 voidaan vähentää yhtälöstä 1, pitää sarjojen olla suppenevia, eli
Kun tämä hässäkkä sijoitetaan alkuperäiseen ongelmaan, saadaan
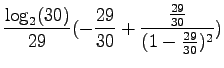 |
|||
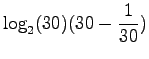 |
|||
Ensi silmäyksellä tämä tulos saattaa tuntua hämmentävältä, eikä tuloksen pitäis olla sama kuin a)-kohdassa? Pikainen tarkistuslasku ehkä hälventää hieman epäluuloja: Sanan pituuden odotusarvo on 29, eli entropia per merkki on n.
On myös syy, miksi tulosten ei pitäisi olla aivan samat: Ensimmäinen lähde voi tuottaa sanan, jossa on kaksi välilyöntiä peräkkäin, kun taas toinen lähde ei voi annetun formuloinnin mukaan sitä tuottaa. Tästä johtuen pitäisi toisen lähteen entropia per merkki olla hieman alempi.
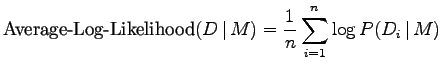 |
Kun logaritmin kantaluku on 2, tämä on itse asiassa (etumerkkiä vaille) risti-entropian suurimman uskottavuuden estimaatti. Kun muokkaamme lauseketta hieman, huomaamme vielä että tämä risti-entropian estimaatti on hämmentyneisyyden (perplexity) logaritmi:
![$\displaystyle - \frac{1}{n} \sum_{i=1}^n \log P(D_i \,\vert\,M) =
\sum_{i=1}^n ...
...{1}{n}}
= \log \big[ ( \prod_{i=1}^n P(D_i \,\vert\,M) )^{-\frac{1}{n} } \big].$](img69.png) |
Huomattakoon, että näissä kaavoissa oletetaan että datapisteiden todennäköisyydet ovat toisistaan riippumattomia. Kielen mallinnuksessa näin ei yleensä ole, vaan tarkka lauseke todennäköisyyksille olisi tekstiä ennustavassa mallissa
Seuraavaksi itse laskuihin:
- a)
- Merkitään mallin yksi antamaa hämmentyneisyyttä
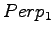 , mallin 2
puolestaan
, mallin 2
puolestaan 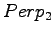 ja niin edelleen.
ja niin edelleen.
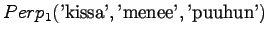
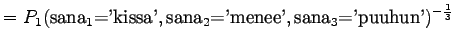
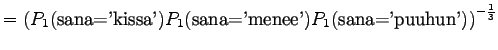
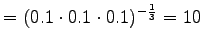
Malli 1 siis valitsee koko ajan keskimäärin kymmenestä eri sanasta. Tulos vaikuttaa oikealta. Entäpä malli 2?
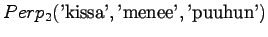
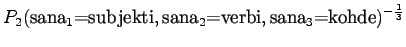
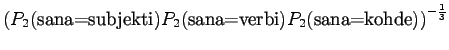
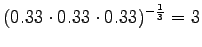
Malli 2 valitsee keskimäärin 3:sta eri vaihtoehdosta, tulos vaikuttaa järkevältä.
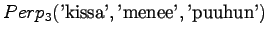
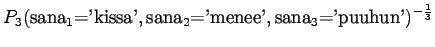

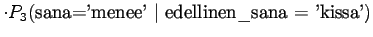
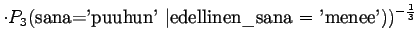
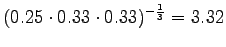
Tämä malli valitsee siis keskimäärin 3.32 sanasta koko ajan.Tämän esimerkin valossa kielimallit 1 ja 3 ovat vertailukelpoiset. Kielimalli 3 vaikuttaa näistä selvästi paremmalta. Kielimalli 2 ei voi verrata muihin, sillä se operoi selvästi pienemmällä symbolijoukolla. Selvempi esimerkki olisi ehkä kielimalli, jonka mielestä kaikki sanat kuuluvat ryhmään 1 ja tämän ryhmän todennäköisyys on siis 1. Tämä kielimalli siis hämmentyneisyyden mukaan täydellinen, sillä se ei ole yhtään yllättynyt mistään sanasta.
- b)
- Tarkastellaanpa vielä toista testilausetta. Mallille 1
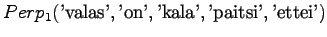

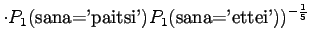
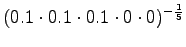
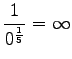
Huomataan, ettei hämmentyneisyyttä voida laskea, jos malli asettaa testijoukon sanalle todennäköisyyden nolla. Usein nämä sanat jätetään huomiotta ja saadaan siis
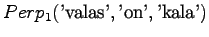
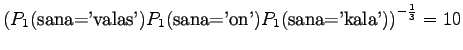
Jotta tulos olisi mielekäs, on nyt myös ilmoitettava ohi kieliopin menneet sanat, tässä tapauksessa siis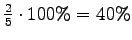 sanoista ei
osunut kielioppiin. Mallille 2 sadaan vastaavasti
sanoista ei
osunut kielioppiin. Mallille 2 sadaan vastaavasti
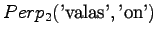
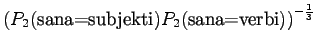
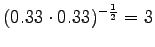
Ohi kieliopin menee myös 60% sanoista.Malliin kolme sopii vain kaksi ensimmäistä sanaa:
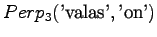
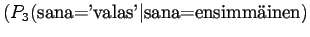
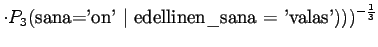
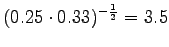
Tässä siis 60% sanoista menee ohi kieliopin.Ovatko b)-kohdan tulokset vertailukelpoisia? Malli 2 voidaan diskata samoilla perusteilla kuin a)-kohdassakin. Malleja 1 ja 3 voidaan vertailla, kun otetaan myös huomioon ohi kieliopin menneet sanat. Malli 1 kattaa sanaston paremmin, mutta malli 3 antaa paremman hämmentyneisyyden. Usein kielimallin laatiminen on tasapainottelua näiden kahden ominaisuuden välillä.