Puhesignaalista on saatu laskettua piirrevektorit
![]() .
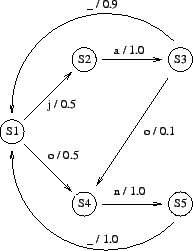
Taulukossa 1 on kaarien jakaumasta lasketut
havaintotodennäköisyydet kunkin vektorin kohdalle.
.
Taulukossa 1 on kaarien jakaumasta lasketut
havaintotodennäköisyydet kunkin vektorin kohdalle.
- a)
- Laske todennäköisin tilajono havainnoille viterbi-algoritmin
avulla. Tilajonon pitää loppua ja alkaa tilasta
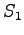 . Mikä sana tai
sanajono tilasiirtymistä muodostuu?
. Mikä sana tai
sanajono tilasiirtymistä muodostuu?
- b)
- Käytetään tunnistuksessa apuna kielimallia. Tehtävän kannalta
relevantit kielimallitodennäköisyydet ovat seuraavat:
Laske todennäköisin tilajono ja sitä vastaava(t) sana(t). Parhaat polut täytyy laskea jokaiselle sanahistorialle erikseen. Kerro kielimallitodennäköisyys mukaan heti sanan valinnan yhteydessä.
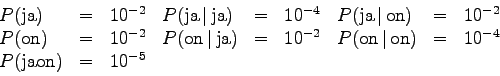
Opetusaineistosta on opetettu kaksi erilaista tilastollista sanojan pilkontaa morfeiksi, A ja B. Samasta aineistosta on opetettu kolme eri kokoista kielimallia kummallekin pilkonnalle. Koot ovat mallien sisältämien n-grammien määriä. Erillisestä sadantuhannen sanan testiaineistosta on laskettu kaikille malleille risti-entropiat yksikköä kohti. Tulokset on esitetty taulukossa 2.
Lisäksi kielimalleja testataan puheentunnistusjärjestelmässä. Tunnistustuloksista lasketaan virheellisesti tunnistettujen sanojen osuus (word-error-rate, WER). Luvut ovat taulukossa 3.
Selvitä annettujen tulosten perusteella kumpi malleista vaikuttaa toimivan paremmin entropiatestien mukaan? Entä tunnistuskokeiden valossa? Kuinka luotettavina johtopäätöksiä voi pitää?