Laite kertoo meille, että erään sanan ``siitä'' perusmuoto on ``siittää''. Millä todennäköisyydellä laite on oikeassa?
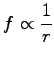 |
Sanallisesti sanottuna siis
Päteekö Zipfin laki satunnaisesti generoidulle kielelle, jossa on 30 kirjainta, joista yksi on sanaväli?
- a)
- Heitetään 101-sivuista noppaa, jonka sivuilla on luvut 0 - 100. Laske saadun silmäluvun odotusarvo ja varianssi. Hahmottele todennäköisyyden p(X) kuvaaja jossa X on heiton silmäluku.
- b)
- Heitetään kahta 101-sivuista noppaa ja jaetaan silmälukujen summa kahdella. Laske tuloksen odotusarvo ja varianssi. Hahmottele todennäköisyyden p(X) kuvaaja jossa X on heiton silmälukujen summa jaettuna kahdella.
- c)
- Ja vielä heitetään kymmentä noppaa, jaetaan tulos kymmennellä. Hahmottele kuvaaja.
- d)
- Etsitään käsiimme kaikki maailman nopat (
 ). Millainen jakauma meillä nyt mahtaa olla? Hahmottele kuvaaja.
). Millainen jakauma meillä nyt mahtaa olla? Hahmottele kuvaaja.
Ideaalinen pienin kuvauspituus on osoitettu mahdottomaksi löytää, ja siksi
menetelmästä on vähemmän objektiivisia mutta käyttökelpoisempia versioita.
Kaksiosaisessa koodausmenetelmässä (two-part coding scheme) valitaan ensin
mallien luokka, joka kuvaa dataa annetulla parametrijoukolla ![]() .
Tarkoitus on kuvata ja lähettää pienimmällä mahdollisella bittimäärällä
datajoukko
.
Tarkoitus on kuvata ja lähettää pienimmällä mahdollisella bittimäärällä
datajoukko ![]() , jonka oletetaan olevan generoitu jollain luokan malleista.
Vastaanottaja tietää mallien luokan, muttei sen parametrien arvoja, joten
myös ne pitää lähettää. Merkitään parametrien kuvauspituutta
, jonka oletetaan olevan generoitu jollain luokan malleista.
Vastaanottaja tietää mallien luokan, muttei sen parametrien arvoja, joten
myös ne pitää lähettää. Merkitään parametrien kuvauspituutta ![]() :lla
ja data kuvauspituutta, kun mallin parametrit tiedetään,
:lla
ja data kuvauspituutta, kun mallin parametrit tiedetään,
![]() :lla.
Tarkoitus on minimoida kokonaiskuvauspituus
:lla.
Tarkoitus on minimoida kokonaiskuvauspituus
![]() .
.
Tilastollisessa mallinnuksessa malliluokan koodausta vastaa
todennäköisyysjakauma
![]() ja parametrien koodausta
jakauma
ja parametrien koodausta
jakauma ![]() .
Informaatioteoriasta tiedämme, että jos viestin todennäköisyys on
.
Informaatioteoriasta tiedämme, että jos viestin todennäköisyys on ![]() ,
sen optimaalinen koodauspituus on
,
sen optimaalinen koodauspituus on
![]() bittiä. Näytä, että
parametrien valinta kaksiosaisessa koodausmenetelmässä vastaa
mallin posterioiritodennäköisyyden valintaa Maximum A Posteriori
(MAP) -estimoinnissa.
bittiä. Näytä, että
parametrien valinta kaksiosaisessa koodausmenetelmässä vastaa
mallin posterioiritodennäköisyyden valintaa Maximum A Posteriori
(MAP) -estimoinnissa.