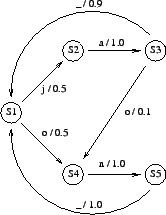
We have a speech signal from which we have calculated the feature
vectors
![]() . In Table 1 there are emission
probabilities of the edges for each vector.
. In Table 1 there are emission
probabilities of the edges for each vector.
- a)
- Find the most probable state sequence using the Viterbi
algorithm. The sequence should start and end with state
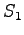 . What
word or word sequence is obtained?
. What
word or word sequence is obtained?
- b)
- Let's utilize a language model for the recognition task.
The relevant probabilities are the following:
Again, find the most probable state sequence and the corresponding word(s). Note that the path of the Viterbi algorithm must be calculated separately for all possible words. Multiply the language model probability to the estimates every time a new word is selected.
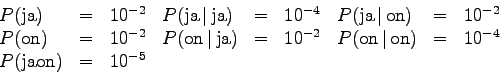
Assume that we have trained two different statistical word segmentations, A and B, from a training corpus. Using the same corpus, we have trained three language models of different size for the units of both segmentations. The sizes are the numbers of n-grams in the models. From a separate 100000 word evaluation corpus we have calculated tokenwise cross-entropies for all of the models. The results are presented in Table 2.
In addition, the models have been tested in a speech recognition system. The recognition results are evaluated with word error rate (WER), which is the percentage of words recognized incorrectly. The results are in Table 3.
Find out which one of the segmentations work better based on the cross-entropy and speech recognition results. How reliable conclusions can be made based on this data?